Keyword

Paper
SCARF: SELF-SUPERVISED CONTRASTIVE LEARNING USING RANDOM FEATURE CORRUPTION
Dara Bahri / Google / 2022.05
https://arxiv.org/pdf/2106.15147.pdf
(Github address)
Abstract
- 기존의 연구들은 괄목할만한 성과가 있었음에도 불구하고 (e.g. autoencoder), domain의 바운더리에서 벗어나질 못했다. 실제 세상에서 tabular 한 데이터에도 도메인 상관없이 범용적으로 쓸 수 있는 모델이 없었다.
- SCARF는 입력 데이터의 일부 특징을 무작위로 선택하여 해당 특징들의 확률 분포에서 샘플링한 값으로 대체하여 입력 데이터의 뷰를 생성하는 방법
- 실제 72개 데이터셋에 검증된바로는 supervised learning 뿐만 아니라 label noise가 있는 semi의 경우에서도 성능이 개선되었다.
- 더불어 다른솔루션과 결합하면 성능이 더 개선되었고, 전반적인 하이퍼파라미터에 stable하다.
We generate a view for a given input by selecting a random subset of its features and replacing them by random draws from the features’ respective empirical marginal distributions. Experimentally, we test SCARF on the OpenML-CC18 benchmark (Vanschoren et al., 2013; Bischl et al., 2017; Feurer et al., 2019), a collection of 72 real-world classification datasets. We show that not only does SCARF pre-training improve classification accuracy in the fully-supervised setting but does so also in the presence of label noise and in the semi-supervised setting where only a fraction of the available training data is labeled. Moreover, we show that combining SCARF pre-training with other solutions to these problems further improves them, demonstrating the versatility of SCARF and its ability to learn effective task-agnostic representations. We then conduct extensive ablation studies, showing the
effects of various design choices and stability to hyperparameters. Our ablations show that SCARF’s
way of constructing views is more effective than alternatives. We show that SCARF is less sensitive
to feature scaling and is stable to various hyperparameters such as batch size, corruption rate, and
softmax temperature.
SCARF Model
- unsupervised pretraining -> supervised fine-tuning
- A part : (Op.Adam, lr:0.001, batch:128, earlystop, max_epoch:1000, corruptionrate:0.6, Temp:1)
- 미니배치에 속하는 레이블 없는 샘플 xi에 대해 노이징된 또다를 x~i를 생성.i
- 일부를 랜덤하게 샘플링하고 이를 분포상 임의추출로 대체하여 균일한 분포가 될 수 있게 함
- 그리고 xi와 x~i 둘다 인코더에 넣으면 거기서 f(encoder)가 돌고,
- f의 output이 g(pretrain head)에 들어가서 최종 zi와 z~i를 뽑는다.
- B part : (Op.Adam, lr:0.001, batch:128, max_epoch:200)
- 동시에 병렬로 같은 인풋은 f를 거쳐 분류하는 h 를 통과한다.
공동 ReLU, hidden 256
f : encoder. input을 latent space로 인코딩하여 벡터형태로 변환 (4 layers)
g : nomalize. 2-normalize하여 infoNCE loss 계산에 도움을 줌 (2 layers)
h : classification. 인코더 f의 출력을 받어 분류작업을 수행 (2 layers)
2-normalize : 벡터를 길이가 1인 벡터로 만드는 정규화 방법 중 하나로, 주어진 벡터를 모든 원소의 제곱합이 1이 되도록 조정합니다. 이렇게 하면 벡터가 유닛 초구면(sphere) 상에 위치하게 되어, 분류 작업에서 벡터 간의 거리 계산이 보다 쉽고 정확해지며, InfoNCE 대비 손실 계산에도 도움이 됩니다.

논문에 나온 g 함수 코드

Dataset
69 datasets from the public OpenML-CC1
Three types datasets
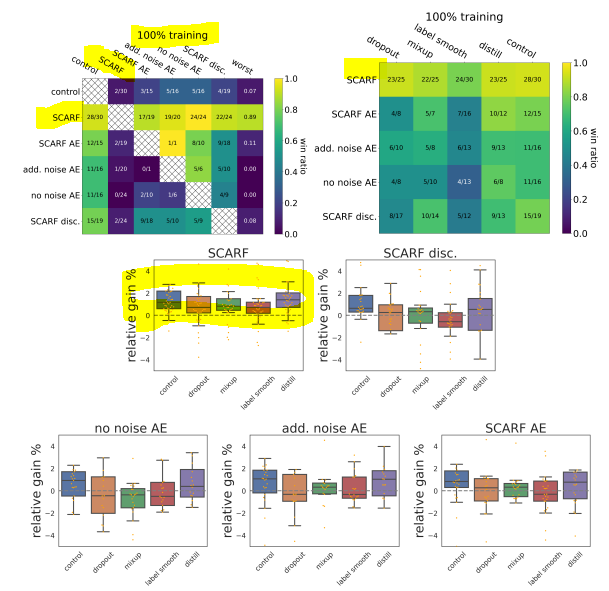
1. 100% labels (fully-supervised)
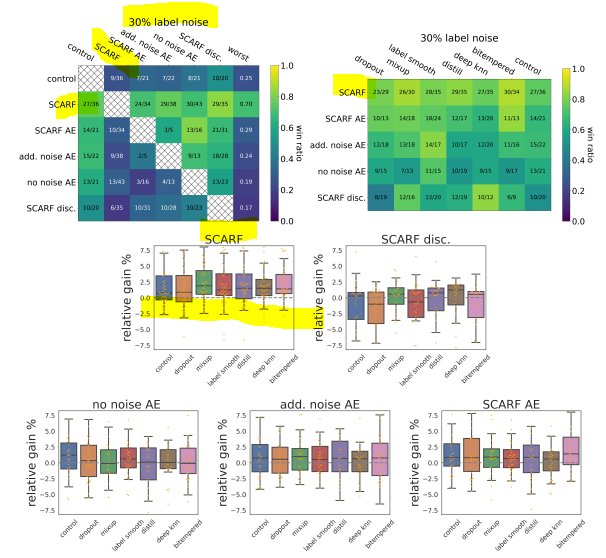
2. 30% fracted lables (for just trainset) (w/noise)
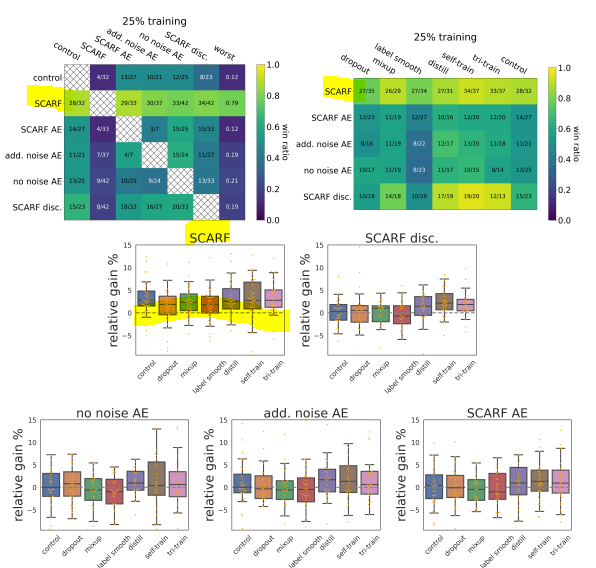
3. 25% labels (semi-supervised)
Ratio of datasets
70%/10%/20% train/validation/test
Preprocessting
categorical data -> one hot
numeric data -> z-score scailing
Evaluation Matrix

Result of experiment




댓글