Keyword

Paper
Exploiting Negative Preference in Content-based MusicRecommendation with Contrastive Learning
Minju Park/SNU/2022.07
https://arxiv.org/pdf/2207.13909.pdf
Points
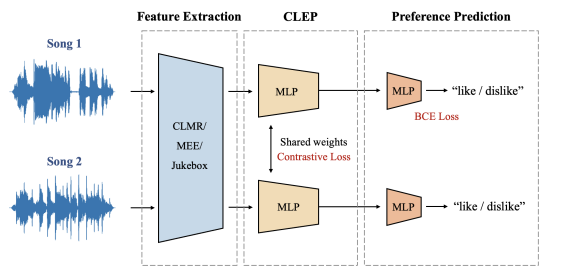
- 추천은 좋아하는 것을 제시하는 것보다 싫어하는 것을 제시하지 않는 것이 더 중요하다.
- 즉, recall이 아니라 False Positive Rate가 더 중요하다.
- CLEP-N가 FPR 부문에서 우수하다.
- 여기서는 추천까지 3단계를 나누어서 설명했고, 이 중 CLEP에 비중을 두고 있다.
- 세 개의 임베딩으로 거리와 마진을 구해낸다.
Feature Exracting
SimCLR :performs contrastive learning by designating different sections of the same song as positive
samples and sections of different songs as negative samples. 같은곡의 cropped 샘플들은 positive, 다른곡의 샘플들은 negative로 해서 추후 분류문제를 해결.
MEE : capture the song’s overall timbre and mood, including its mastering style. CLMR은 음악의 리듬, 멜로디 같은 구성요소를 고려해 특징을 추출, MEE는 추가적으로 음악 톤, 분위기, 마스터링 스타일 등을 고려해서 음악의 특성을 더 정확히 추출. 자료가 많아지고 표현이 풍부해짐.
Jukebox : using the architecture of hierarchical VQ-VAE and its encoder successfully represents the music with latent vectors. VQ-VAE인코더를 이용한 주크박스는 음악의 latent vector를 더 잘 담을 수 있음

Contrastive Learning Exploiting Preference (CLEP)
• CLEP-PN Model with contrastive learning exploiting both positive and negative preferences: 좋아요-좋아요쌍이나 싫어요-싫어요쌍이 y=1, 나머지는 0
• CLEP-P Model with contrastive learning exploiting positive preference only 좋아요-좋아요만 y=1.
• CLEP-N Model with contrastive learning exploiting negative preference only 싫어요-싫어요만 y=1

Preference Prediction
일반적인 다중퍼셉트론에 binary cross entropy loss로 input으로 들어온 음악에 대한 사용자의 선호도를 sigmoid한 확률값으로 output.

it is reduced when validation loss is not decreasing until two epochs 2 에포크 내에 val_loss가 줄지 않는 케이스를 줄였다? 즉, 2번 안에도 val_loss가 잘 줄어들더라.
Loss
CLEP stage : CL loss

Prediction : BCE loss
Results
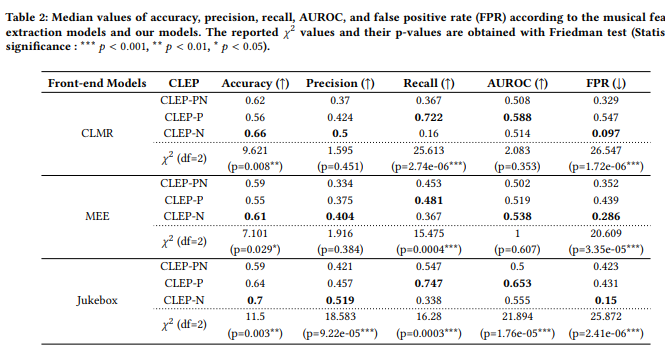
1. FPR이 중요하다. 그런데 데이터셋에 따라 FPR 차이가 있다. 어떤 데이터 형식에 더 잘 학습되는 걸까
2. a chance of finding songs the user may like in an unpredictable area of he user’s music taste, and the findings of our work explain it.
- CLMR: 이 데이터셋은 MagnaTagATune이라고도 불리며, 25,863개의 음악 트랙으로 구성되어 있습니다. 이 데이터셋은 음악 장르, 악기, 분위기 등 다양한 음악적 특징을 레이블로 제공합니다.
- MEE: 이 데이터셋은 MTG-Jamendo라고도 불리며, 약 200,000개의 음악 트랙으로 구성되어 있습니다. 이 데이터셋은 음악의 장르, 악기, 템포 등을 레이블로 제공합니다.
- Jukebox: 이 데이터셋은 수십만 개의 노래를 수집하기 위해 웹 크롤링을 사용하여 만들어졌습니다. 이 데이터셋은 일부 노래에 대한 가사, 장르, 곡 작곡가, 가수 등의 정보를 제공합니다.
- 같은 추천 시스템 모델을 사용하여 학습시켰을 때 False positive rate가 차이가 나는 이유는 여러 가지 일 수 있습니다. 예를 들어, 데이터셋의 크기, 레이블의 품질, 데이터셋 내의 클래스 균형, 모델의 복잡도, 하이퍼파라미터의 선택 등이 영향을 미칠 수 있습니다. 따라서 이러한 요인들을 고려하여 모델을 학습시켜야합니다. (from GPT)

t-SNE는 t-distributed stochastic neighbor embedding의 약자로, 고차원 데이터를 시각화하기 위해 사용되는 비선형 차원 축소 기술 중 하나입니다.
Limitation
- 그래서 이를 기반으로 추천하였을 때 더욱 만족도가 높았는지, 다른 뮤직컨텐츠 소비가 늘었는지에 대한 객관적인 결과지표가 없다.
- 음악을 하는 사람들은 보통 음악의 스펙트럼이 넓고 새로운 장르에서도 영감을 얻는 경우가 종종 있다는 것을 인지하고 있기 때문에, dislike라고 명시적인 지표를 표현하는 수가 과연 많을지는 의문인듯..




댓글