Attention
https://arxiv.org/pdf/1409.0473.pdf
0. Abstract
The models proposed recently for neural machine translation often belong to a family of encoder–decoders and encode a source sentence into a fixed-length vector from which a decoder generates a translation. In this paper, we conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder–decoder architecture, and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly
1. Introduction
Basic Encoder-Decoder model
An encoder neural network reads and encodes a source sentence into a fixed-length vector. A decoder then outputs a translation from the encoded vector. The whole encoder–decoder system, which consists of the encoder and the decoder for a language pair, is jointly trained to maximize the probability of a correct translation given a source sentence.
Problems
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus. Cho et al. (2014b) showed that indeed the performance of a basic encoder–decoder deteriorates rapidly as the length of an input sentence increases.
How to solve
The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. We show this allows a model to cope better with long sentences.
2. Background
arg maxy p(y | x).
a given source sentence (x) 가 주어졌을 때의 target y의 조건부확률의 max.
RNN
x : a variable-length source sentence into a fixed-length vector
y : decode the vector into a variable-length target sentence. (sos, eos 토큰을 통해 원하는 길이만큼 생성 가능)

3. Details
인코더 hidden state와 디코더 hidden satate간의 유사도를 계산하여 hidden state의 중요도를 구하고,
이를 이용하여 다음 단어를 생성할 때 어떤 hidden state를 중심으로 정보를 수집할 지 결정한다.
the probability is conditioned on a distinct context vector ci for each target word yi .
가장 크게 바뀌는 부분은 c 가 ci가 되는 부분이다.
즉, 인코더가 X를 해석한 context 는 디코더의 포지션 i에 따라 다르게 표현(represent)되어야 한다.
- i : 디코더의 인덱스
- j : 인코더의 인덱스
ci는 현재 인덱스의 context vector로 단순히 시간의 개념만 붙은 것이 아니다.
I love you를 한글번역할 때, i=0인 i를 '나'로 만들어야 할 때에는, 컨텍스트 벡터 중 love you 보다 I가 강조되어야 하기 때문에 이렇게 각 스텝마다 더 중요하게 생각해야 하는 부분이 있다는 것을 가중치 aij를 곱해 해결했다.
aij는 인코더의 j번째 hidden state hj가 얼마나 강조되어야 할지를 나타내는 가중치이다.
이 가중치는 디코더의 직전 스텝의 hidden state인 si-1와 현재 i시점의 인코더 hidden state인 hi의 유사도가 높을수록 값이 높다. 즉, 지금 번역해야하는 그 시점에 무게를 실어준다.
aij의 총 sum은 1이고, softmax로 구해진 확률값이다.
An alignment model which scores how well the inputs around position j and the output at position i match. The score is based on the RNN hidden state si−1 (just before emitting yi , Eq. (4)) and the j-th annotation hj of the input sentence.
즉, ci = 지금 번역해야할 그 시점에 가장 중요하게 봐야하는 부분까지 softmax로 계산된 확률에, 해당 인코더 인덱스의 hidden state 값을 곱해준 "가중치 of the 가중치s 들의 sigma" 모양이다.
Let αij be a probability that the target word yi is aligned to, or translated from, a source word xj . Then, the i-th context vector ci is the expected annotation over all the annotations with probabilities αij . The probability αij , or its associated energy eij , reflects the importance of the annotation hj with respect to the previous hidden state si−1 in deciding the next state si and generating yi . Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixedlength vector. With this new approach the information can be spread throughout the sequence of annotations, which can be selectively retrieved by the decoder accordingly.
여기서 hidden state로 나오는 hj는 사실 조금 더 들어간다.
Bidirectional RNN으로 backpropagated되는 것이라, forward + backward가 concatede 된 모양이다.
hj는 xj에 관련된 앞으로, 뒤로의 모든 정보를 풍부하게 가진다.
A BiRNN consists of forward and backward RNN’s. The forward RNN −→f reads the input sequence as it is ordered (from x1 to xTx ) and calculates a sequence of forward hidden states ( −→h 1, · · · , −→h Tx ). The backward RNN ←−f reads the sequence in the reverse order (from xTx to x1), resulting in a sequence of backward hidden states ( ←− h 1, · · · , ←− h Tx ). We obtain an annotation for each word xj by concatenating the forward hidden state −→h j and the backward one ←− h j , i.e., hj = h−→h > j ; ←− h > j i> . In this way, the annotation hj contains the summaries of both the preceding words and the following words. Due to the tendency of RNNs to better represent recent inputs, the annotation hj will be focused on the words around xj . This sequence of annotations is used by the decoder and the alignment model later to compute the context vector.
1 단계 : 모든 인코더 hidden state의 점수 얻기
2 단계 : 모든 점수를 softmax 레이어를 통해 실행하십시오.
3 단계 : 각 인코더 hidden state에 softmaxed 점수를 곱합니다.
4 단계 : 얼라이먼트 벡터를 합하십시오.
5 단계 : 이전 디코더 시각 단계 (분홍색)의 출력 + 현재 시각 단계의 context 벡터 (진한 녹색) (concat)
6 단계 : context 벡터를 디코더에 전달하십시오.
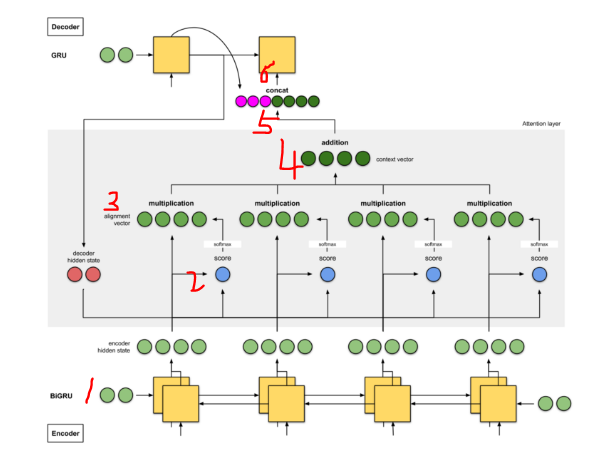
Q14. 위 시각화 글의 2단계에서, Softmax의 결괏값은 Encoder에 매 스텝마다 입력으로 들어온 각 단어의 독립적인 비중이라고 생각해도 좋은가요? (Hint: RNN의 Hidden State는 어떤 과정을 통해 생기죠?)
>> 독립적이지 않다. RNN은 단어의 정보를 순차적으로 적립하여 Hidden State를 구축하기 때문에 순방향 RNN의 첫 단어는 그 단어의 정보만을 담았을지언정 그 이후 스텝들은 거쳐온 모든 단어의 정보를 포함하고 있다.
Q15. 위 시각화 글의 4단계에서, Hidden State에 Softmax 값을 곱하여 Alignment 값을 얻었습니다. 해당 값을 모두 더하여 최종적인 컨텍스트 벡터를 얻는데요, 다 더해지면 값이 모호해지지 않을까요? 이는 어떤 의미를 갖나요? 간단히 설명하고 기존 Seq2seq의 고정 크기의 컨텍스트 벡터와 비교해봅시다. (Hint: Word2Vec의 연산을 기억하나요?)
>>컨텍스트 벡터가 핵심 단어(비중이 큰 단어)에 가장 근접하게 다가서되, 주변 단어에도 각각의 비중만큼 영향을 받아 문장을 적합한 위치에 매핑되게 한다.
기존 RNN의 최종 스텝을 컨텍스트 벡터로 쓰던 방식은 항상 고정된 비중을 사용(마지막에 등장한 단어가 큰 비중)하는 셈이므로 Bahdanau의 방식보다 문맥 정보를 유연하게 반영하지 못한다.
Q16. Bahdanau 방식에서 생성된 컨텍스트 벡터는 어떤 방식으로 Decoder에서 사용되나요?
>>Decoder의 이전 Hidden State와 Concatenate하여 새로운 Hidden State로 정의된다.
4. Types
Bahdanau Attention
Bahdanau attention에서 사용되는 평가 함수는 내적이 아닌, 일반적으로 다음과 같이 계산됩니다.
우선, 인코더의 Hidden State를 모두 벡터로 표현합니다. 그리고 디코더의 이전 Hidden State를 벡터로 나타낸 후, 두 벡터를 각각 특정 벡터 공간으로 매핑합니다. 이때 매핑 함수는 일반적으로 하나의 선형 계층으로 구성됩니다.
매핑된 두 벡터를 더한 후, tanh 함수를 이용하여 범위를 [-1, 1]로 변환합니다. 이렇게 만들어진 벡터를 가중치 벡터와 내적합니다. 가중치 벡터는 학습 과정에서 학습됩니다. 이 내적값이 바로 Bahdanau attention에서 사용되는 평가 함수입니다.
즉, 내적이 아닌 특정 벡터 공간으로 매핑된 두 Hidden State를 더하고, tanh 함수를 이용하여 범위를 변환한 후, 가중치 벡터와 내적하여 평가 함수를 계산합니다.
Bahdanau attention에서 사용되는 평가 함수는 이전 Hidden State와 현재 Hidden State 사이의 유사도를 측정하여, 현재 Hidden State가 이전 Hidden State와 얼마나 유사한지를 판단하는데 사용됩니다. 이를 이용하여 현재 Hidden State가 어떤 인코더의 Hidden State를 중심으로 정보를 수집해야 하는지를 결정합니다.
1단계의 내적 부분이 이렇게 됨.
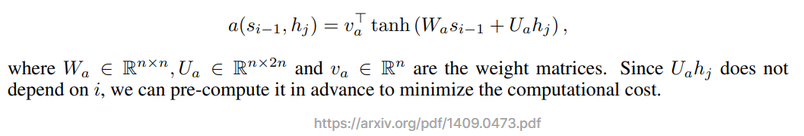
Luong attention
Luong attention은 Bahdanau attention과 유사하지만, 평가 함수가 다르게 계산됩니다.
우선, Bahdanau attention과 마찬가지로 인코더의 Hidden State와 디코더의 Hidden State 사이의 유사도를 측정하기 위해 두 벡터를 연결(concatenate)하여 하나의 벡터로 만듭니다. 이때, Bahdanau attention과는 달리, 연결된 벡터를 바로 평가 함수에 입력하지 않고, 하나의 선형 계층을 거쳐서 비선형 활성화 함수인 tanh를 거쳐 벡터를 변환합니다.
변환된 벡터와 인코더의 Hidden State를 곱하여 점수를 계산합니다. 이때, 곱하는 방식에는 dot product, concat 방식, general 방식 등 여러가지 방식이 있습니다.
- Dot product 방식: 변환된 디코더 Hidden State와 인코더 Hidden State의 dot product를 계산합니다.
- Concat 방식: 변환된 디코더 Hidden State와 인코더 Hidden State를 concatenate한 후, 하나의 선형 계층을 거쳐 점수를 계산합니다.
- General 방식: 인코더 Hidden State를 변환하는 선형 계층을 따로 두어, 이를 이용하여 점수를 계산합니다.
- Location 방식: 인코더 시퀀스에서 어디에 집중해야 할지를 결정하는 데 사용되는 방식입니다. 이 방식은 이전 타임 스텝에서 디코더가 생성한 단어와 현재 타임 스텝에서 디코더가 생성할 단어를 고려하여, 인코더 시퀀스에서 집중해야 할 위치를 결정합니다.
이렇게 계산된 점수는 softmax 함수를 이용하여 정규화되어, 각 Hidden State의 가중치를 계산합니다. 이 가중치를 이용하여 각 Hidden State의 정보를 조합하여 디코더가 다음 단어를 생성할 때 사용됩니다.
따라서 Luong attention은 Bahdanau attention과 유사하지만, 평가 함수가 다르게 계산되며, dot product, concat, general 방식 중 하나를 선택하여 계산할 수 있습니다.
Bahdanau의 Score 함수와는 다르게 하나의 Weight만을 사용하는 것이 특징입니다. 어떤 벡터 공간에 매핑해주는 과정이 없기 때문에 Weight의 크기는 단어 Embedding 크기와 동일해야 연산이 가능합니다.
https://eda-ai-lab.tistory.com/157
Attn: Illustrated Attention
원문 아티클 : Attn: Illustrated Attention Attn: Illustrated Attention GIFs를 활용한 기계번역(ex. 구글번역기)에서의 Attention 신경망을 활용한 기계 번역모델(NMT)이 나오기 전 수십 년 동안, 통계기반 기계 번역
eda-ai-lab.tistory.com
'Study (Data Science) > NLP' 카테고리의 다른 글
| Transformer 1 - Positional Encoding (0) | 2023.03.09 |
|---|---|
| 모델 발전과정 3 - GNMT (Google's Seq2seq 8 layers w. Residual) (0) | 2023.02.28 |
| 모델 발전과정 1 - SLM / NNLM / RNN / Seq2seq (0) | 2023.02.27 |
| 벡터화 발전과정 4 - 워드 임베딩 (Word2Vec / FastText / GloVe) (0) | 2023.02.23 |
| 벡터화 발전과정 3 - 임베딩 (Embbeding) / Sparse - Dense - Embedding vector (0) | 2023.02.22 |



댓글