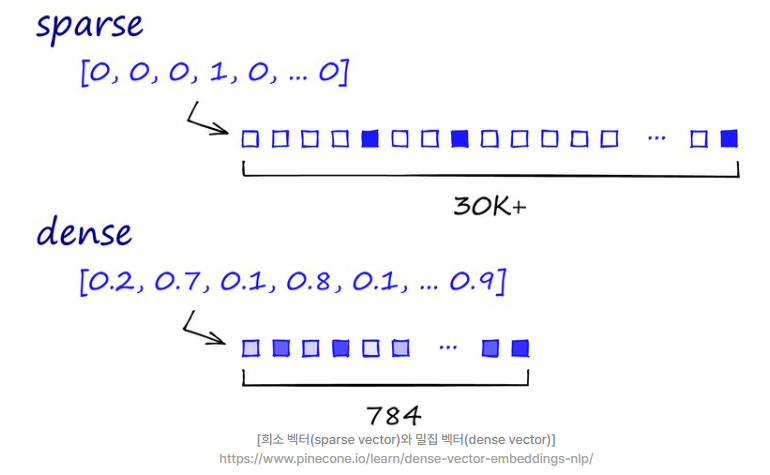
희소 벡터 (sparse vector) 들이 난무하는
DTM, TF-IDF, 원-핫 벡터 단어장에는 0이 너무 너무 많다.
단어장의 크기가 커지면, 그만큼 차원이 늘어면서 차원의 저주(curse of dimensionality)가 시작된다.
차원의 저주란, 희소벡터의 비율이 같은 일정 데이터를 2D에 표현했을 때보다, 3D로 표현했을때
더 density가 떨어진다는 뜻이다. 골다골증인 것처럼 데이터에 구멍이 송송송송 빈다.
데이터가 많으면 많을 수록 표현이 잘 되고 좋은 것은 맞지만,
필요없는 0 같은 노이즈가 많이 끼면 오히려 학습에 방해가 되고,
학습을 마치더라도 유의미한 결과라고 하기 어렵다.
그래서 Sparse vector 를 Dense vector 로 바꾼다.
즉, 벡터 하나하나 의미가 있는 아이들로 꽉꽉 채워넣는 것이다.
그러면 차원이 너무 높을 필요도 없고,
정보가 알차게 들어차기 때문에 훨씬 효율적이다.
같은 이유로 데이터의 차원이 커지면 더 많은 정보를 담을 수 있게 되므로
무조건 ML 모델의 성능이 올라간다는 말은 맞지 않다.
sparse vector는 사실 0이 많이 끼어있는 sparse matrix에서 시작된 개념이지만
matrix 자체의 형태를 비유한 것이 아니라, 각 요소들, 즉 벡터들을 지칭했다는 점이 다르다.
임베딩은 여기서 한번 더 나간다.
TD-IDF는 해당되지 않지만, 원-핫 인코딩 같은 경우는 그냥 0과 1로 막 그냥 막 그냥 아주 그냥 푼거라서
각 벡터간의 유사도를 계산할 수는 없다.
즉 강아지와 고양이가 비슷하다는 것을 사람은 느끼지만,
컴퓨터도 느낄 수 있도록 만들어줘야 하는데,
원-핫으로는 이런 힌트를 조금도 줄 수가 없다.
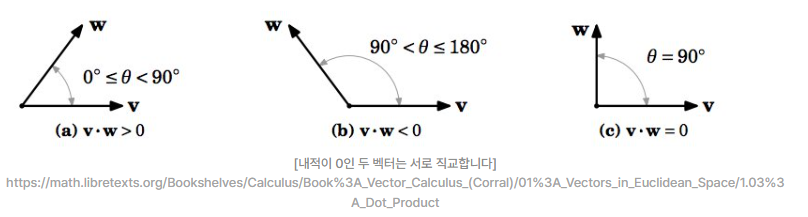
왜냐하면 컴퓨터가 비슷하다는 것을 느끼려면 inner product(내적)을 해야하는데,
원 핫은 대부분이 직교(orthogonal)하기 때문에 유사도가 0이 된다.
그래서 이 유사성을 구하기 위해서
밀집 벡터 (dense vector)를 학습시키는
워드 임베딩이 (word embedding)이 나오게 되었다.
워드 임베딩은 어떻게 되는가
워드 임베딩도 벡터화 하는 것은 똑같은데, 옆으로 길어질 수 있는, 즉 차원이 제한된다.
그래서 표현할 수 있는 길이의 한계치가 있다보니 자연스럽게 그 안에 dense하게 밀집벡터가 될 수 밖에 없다.
밀집 벡터에서는 각 벡터 값의 의미가 파악하기 어려울 정도로 많은 의미를 함축하고 있는데,
워드 임베딩은 이 벡터간의 관계를 수식으로 계산하여 dense vector들을 정하는 과정이다.
이 수식은 앞에서 계산하던 내적보다 훨씬 더 복잡한 수식이 되고 이건 컴퓨터만의 생각하는 flow가 된다.딥러닝은 각 단계별로 수식에 근거하여 계산하면서 주어진 dense vector들을 업데이트한다.이렇게 만들어진 벡터를 우리는
Dense vector가 아닌 Embedding vector 라고 한다.
| 입력차원 多 | 입력차원 少 | 데이터갯수 多 | 데이터갯수 少 | 모델복잡도 低 | 모델복잡도 高 | |
| 언더피팅 | X | △ | X | O | △ | O |
| 오버피팅 | O | X | X | X | O | X |
| 차원의 저주 | O | X | X | X | X | △ |
이건 내 생각이라 정확하지 않지만,,
연습문제라서 풀어봄.
'Study (Data Science) > NLP' 카테고리의 다른 글
| 모델 발전과정 1 - SLM / NNLM / RNN / Seq2seq (0) | 2023.02.27 |
|---|---|
| 벡터화 발전과정 4 - 워드 임베딩 (Word2Vec / FastText / GloVe) (0) | 2023.02.23 |
| 토큰화 / 인덱싱 / 벡터화 / 임베딩 (0) | 2023.02.22 |
| 벡터화 발전과정 2 - soynlp (비지도학습 한국어 형태소 분석기) (0) | 2023.02.20 |
| 벡터화 발전과정 (BoW/DTM/TF-IDF/SVD/LSA/LDA/토픽모델링) (0) | 2023.02.18 |



댓글