- Seq2seq의 Encoder-Decoder를 6개 쌓아올린 모델.
- Enc-Dec x 6 은 아니고, Enc x 6 + Dec x 6임.
- RNN, LSTM 등의 기존 문장의 연속성을 무시
- 이를 무시하니 병렬구조가 가능해져서 연산속도가 엄청 빨라졌음.
- seq2seq처럼 context vector를 중간 병목으로 쓰지 않음.
- Self attention, 즉 내가 들어가서 내가 나오는 재귀적인 구조임.
- 문장의 문맥 + 단어의 순서 (위치)까지 attention에 담았음.
논문 : https://arxiv.org/pdf/1706.03762.pdf (Attention is all you need (2017))
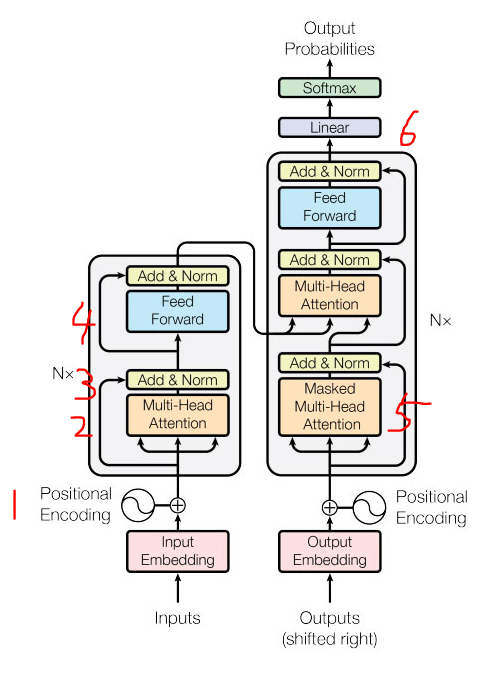
각 모듈이 하는 일을 간단하게 정리하면,
- Positional Encoding: 입력 문장의 단어들에 위치 정보를 추가하기 위한 층으로, 위치 정보를 sinusoidal function을 사용하여 인코딩합니다.
- Multi-Head Attention: 입력 문장의 단어들 간의 상호작용을 모델링하기 위한 층으로, 다양한 관점으로 입력을 처리하기 위해 입력을 여러 개의 서로 다른 선형 투사 공간으로 분할하고 각각을 어텐션(Attention)합니다.
- Add & Norm: Residual Connection과 Layer Normalization을 결합한 층으로, 입력과 출력의 차원이 같은 경우에 덧셈 연산을 통해 입력과 출력을 합산합니다. 이렇게 만들어진 결과물에 Layer Normalization을 적용하여 출력을 정규화합니다.
- Feed Forward: 입력 벡터를 선형 변환하고 활성화 함수를 통해 변환된 값을 출력합니다. 이 층은 각 입력 단어에 대해 독립적으로 처리되기 때문에 병렬 계산이 가능합니다.
- Masked Multi-Head Attention: 디코더에서 사용되는 Multi-Head Attention으로, 현재 위치 이전의 단어들만 고려하여 어텐션을 수행합니다.
- Linear: 입력 벡터를 선형 변환하는 층으로, 일반적인 완전 연결층입니다.
1. Positional Encoding

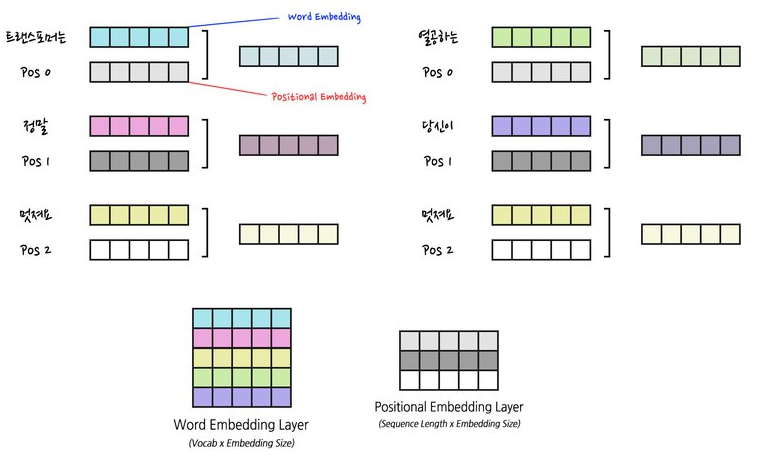
- 위치정보를 임베딩차원으로 입력받아 각 위치의 값을 임베딩에 추가하는 것.
- 그래서 shape이 (위치정보(pos) x 임베딩차원(d_model)).
- 위치정보를 인덱스로 0,1,2 이런식으로 int나 0-1사이의 float으로 표현하는 것이 아니고, 그 정보를 숫자가 아닌 다른 공간상의 벡터로 옮겨서, 각 위치에서 각도를 계산한 벡터를 반환받게 되어있음.
- cal_angle: 각도를 계산하는 함수 / get_posi_angle_vec : 개당 각도벡터를 반환하는 함수로 이뤄져 있고,
- 이를 position의 갯수만큼 반환하게 하는데, 짝수열은 sin, 홀수열은 cos함수로 계산하여 위치정보를 인코딩함.(sinusoidal function)

position / np.power(10000, int(i) / d_model) 이 부분이 각을 구하는 식이되고, 설명하자면,
각 위치(position)에서 i번째 차원의 각도를 계산하기 위해, position을 10000의 d_model지수승으로 나눈 뒤, i/d_model을 정수형으로 변환하여 지수승으로 사용, 이렇게 계산된 값을 사용하여 sin과 cos 함수를 적용하면 해당 위치에서 i번째 차원의 각도를 계산할 수 있음.
코드는 pos = 7번 포지션, d_model = 4차원의 임베딩차원 중 i=0번째, 즉 0차원의 각도값을 구하는 것이고, 대입하면,
7 / np.power(10000,int(0) / 4) = 7 / np.power(10000, 0) = 7 / 1 = 7 이 된다.
0/4=0 10000의 0승은 1
따라서, 위치 7에서 0번째 차원의 각도는 7이다.
이렇게 각 위치별 / 각 차원별 각도를 계산하면 대충 이런 모양이 나오고, 이와 같이 반복적으로 for문을 돌려 계산하게 해주는 함수가 get_posi_angle_vec 이다.
if pos == 0, i == 0: 0.0
if pos == 1, i == 0: 0.8414709848078965
if pos == 2, i == 0: 0.9092974268256817
if pos == 3, i == 0: 0.1411200080598672
if pos == 0, i == 1: 1.0
if pos == 1, i == 1: 0.9950041652780258
if pos == 2, i == 1: 0.9800665778412416
if pos == 3, i == 1: 0.955336489125606이것을 행렬의 줄을 맞춰 적으면 딱
(position갯수 x 정보를 담은 임베딩 dimension) = (pos x d_model) = (7, 4) 이다.
7개의 단어가 한 문장이고, 각 단어의 정보를 4 깊이만큼 표현했다는 뜻이다.
워드임베딩은 단어의 의미에 대해 깊이 표현했다면, 이건 깊이에 대한 정보를 deep하게 표현한 것이다.
그리고, sinusoid_table, 즉 encoding된 매트릭스를 얻기 위해서,
포지션 넘버방향 (행방향)으로 짝수행은 sin, 홀수행은 cos 함수를 해서 값을 계산한다.
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(pos)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
예를 들어, i가


세로축 : Time-step
가로축 : Word Embedding에 더해질 Position 값
각 스텝마다 중복없이 고유한 값을 가지고 있다.
Bert에서는 임베딩 정보에 sin, cos 을 담지 않고, Positional 정보를 담는다.
(position갯수 x 위치정보를 담은 임베딩 dimension) 가 되는 셈!
Bert는 나중에 다시 정리할 것.
'Study (Data Science) > NLP' 카테고리의 다른 글
| Transformer 3 - Residential Add / Normalization (0) | 2023.03.14 |
|---|---|
| Transformer 2 - Multi Head Attention / Scaled Dot-Product Attention / Masking / Position-wise Feed Forward Network / Query, Key, Value (0) | 2023.03.14 |
| 모델 발전과정 3 - GNMT (Google's Seq2seq 8 layers w. Residual) (0) | 2023.02.28 |
| 모델 발전과정 2 - Attention (Bahdanau / Luong) (0) | 2023.02.28 |
| 모델 발전과정 1 - SLM / NNLM / RNN / Seq2seq (0) | 2023.02.27 |



댓글