2003년 요슈아 벤지오(Yoshua Bengio) 교수가
NPLM(Neural Probabilistic Language Model) 이란 모델을 통해 제안된 워드 임베딩.
하지만 이 모델은 너무 느렸다.
2013년, 구글이 NPLM의 정밀도와 속도를 개선하여
Word2Vec을 만들었고,
그 이후로 FastText나 GloVe 등과 같은 방법들이 제안되었다..
Word2Vec
원핫보다 저차원이고, neighbor words간 유사도를 가짐
word2vec은 워드임베딩 종류의 하나이고,
Unsupervised or Self learning 이라고도 한다.
왜냐하면 그 유의미한 Dense Vector들을 자기가 학습하면서 기울기를 조정하여 업데이트해가기 때문이다.
분포 가설(Distributional Hypothesis)을 따름
Word2Vec의 핵심 아이디어는 분포 가설(distributional hypothesis) 을 따르며,
단어의 의미는 그 주변의 단어들과의 문맥적 관계로 인해 결정된다는 이론.
window size를 정해주면 (예를 들어 3)
해당 단어에서 좌우까지의 단어를 neighbor 단어로 지정하고
하기와 같이 각각 이웃단어를 기준으로 원핫인코딩을 한다.

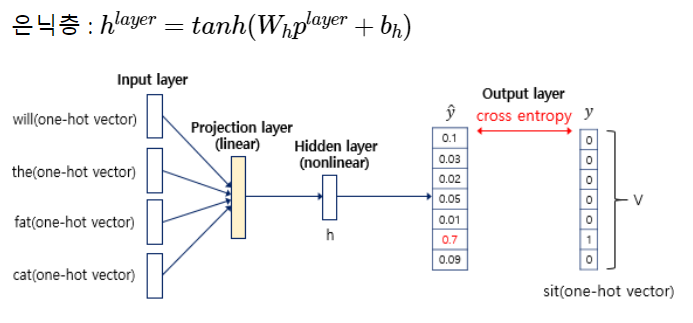
그렇게 변환된 원핫 인코딩 벡터들이 이루어진 문장을 input으로 넣고,
DL을 통해 중간의 hidden layers를 loss 함수를 통해 학습해 가장 최적의 상태로 업데이팅하는데,
그 hidden layer가 word2vec이 되는 것이다.
잠시 살펴보면, input과 output은 모두 6차원인데 비해 hidden은 2차원이기 때문에
같은 king이라는 단어가 있어도
input에서 [1,0,0,0,0] 이었어도, hidden layer의 embedding된 king은 [1,1] 로 표현되는 것이다.
그렇게 모든 단어들을 표현하고 나면,
king = [1,1] , man = [1,3], queen = [5,5], woman=[5,7] 과 같이 표현할 수 있고,
이 모든 단어를 한 공간에 표현해보면,
유사성이 있는 단어들은 가까이 위치한다는 사실을 알 수 있다. (분포가설)
주요 알고리즘 두가지
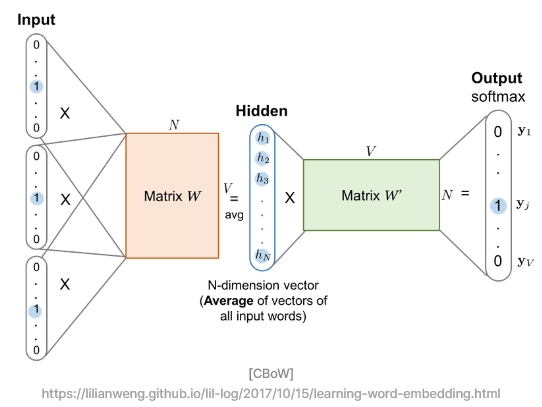
1. CBoW (Continuous Bag of words)
용도 : 중심단어를 예측할 때 사용 (주변단어를 사용하여 예측)
속도 : 여러개의 주변단어로 하나의 중심단어만 예측하니 빠름
장점 : 등장하는 빈도가 많은 단어에 대해서 학습을 잘함
skipgram과 동일하게 window size가 주어지고,
만약 윈도우 단어가 2개라면, 양 옆에 2개 단어씩 참고하게 된다.
(I like ? language processing) very much.
근데 Continuous하다는 뜻은,,
여기서 하나 더 해서 sliding window를 지정하고,
(주변단어 set, 중심단어)의 형식으로, 주변단어와 중심단어를 또 shuffle해 가면서
또 하나의 가중치 행렬을 만들어 간다.

그림처럼 히든레이어 (임베딩 레이어)를 중심으로
양 옆에 orange Weight 와 green Weight 생겨서 가중치가 두 개가 되는데,
이 알고리즘은 Backpropagation 하기 때문에
계속적으로 그 가중치를 업데이트 시켜 나간다.
그렇기 때문에 Word2Vec 는 사실상 하나의 레이어라고 하기 보다는
얕은 인공신경망이라고 보는게 맞다.


2. skipgram
중심 단어로부터 주변 단어를 예측한다는 점,
그리고 이로 인해 중간에 은닉층에서 다수의 벡터의 덧셈과 평균을 구하는 과정이 없어졌다
는 점만 제외하면 CBoW와 메커니즘 자체는 동일
용도 : 주변단어를 예측할 때 사용 (중심단어로 주변단어를 예측)
속도 : 한 개의 중심단어로 여러개의 주변단어를 예측해야해서 속도 느림
장점 : 등장하는 빈도가 적은 단어에 대해서도 학습을 잘함
모델 : 위의 모델을 좌우 반전하면 됨 (input과 output을 바꿔넣음)
네거티브 샘플링 SGNS (Skip-Gram with Negative Sampling)
Skip gram이 연산량이 너무 많아서 사용하는 방법.
중심단어 하나로 여러 주변단어들을 찾다내다보니
그들 각각의 임베딩 벡터 조정을 위해 역전파를 써야해서 연산량이 너무 많고, 느리다.
그래서 중심단어 -윈도우 사이즈만큼의 주변단어들 = 1,
중심단어 - 랜덤으로 뽑아온 안 주변단어들 = 0, 으로 타겟팅을 해버리고
모든 단어에 대해 학습하는 것이 아니라 그 중간에 이진분류를 실행함으로써 연산량을 줄인다.
FastText
페이스북에서 개발한 워드 임베딩 방법.
Word에서 더 작은 문자단위 n-gram을 하여 내부단어(subwords)를 학습하게 한다.
여기서 n = 단어를 n문자단위로 분리하겠다 라는 하이퍼 파라미터로,
만약 n=3이고 단어 partial을 주면,
<pa, par, art, rti, tia, ial, al> 총 7개로 token을 만들어 각각을 벡터로 만든다.
그렇게 해서 각 벡터들에 대해 각각 Word2Vec을 수행하게 된다.
장점 : Word2Vec에서 해결하지 못했던 OOV 문제를 해결할 수 있다.
즉, Word2Vec은 혹여 input에 오타단어 previeww가 있었다면,
학습 후에 preview와 비슷한 단어를 출력해달라고 했을 때, 출력을 못한다.
왜냐하면 preview라는 단어는 Word2Vec의 룩업테이블(단어사전)에 없었기 때문이다.
(거기에는 previeww라는 단어에 대한 정보만 있었음)
하지만 FastText는 아니다.
FastText는 <pr, pre, rev, evi, vie, iew, eww, ww> 에 대한 룩업테이블이 있어서,
preview가 들어와도 이걸 또 <pr, pre, rev, evi, vie, iew, ew>로 나누게 되니,
공동적으로 겹치는 <pr, pre, rev, evi, vie, iew 에 대한 정보가 있어서
연산이 가능하긴 하기 때문에, preview와 비슷한 단어를 찾아달라고 해도 찾아낼 수 있다.
한국어 FastText
한국어는 자소단위로 나눈다.
텐서플로우 라면,
<텐서, 텐서플, 서플로, 플로우, 로우> 가 아니라,
<ㅌㅔ,ㅌㅔㄴ,ㅔㄴㅅ,ㄴㅅㅓ,ㅅㅓ_, ...중략... > 라는 것이다.
이렇게 하면 오탈자 (오타) 가 있어도 결과를 뽑아낼 수 있지만
'프랑스' 같은 고유명사는 자소분해를 해도 별 효과가 없고, 성능을 저하시키기도 한다.
GloVe
스탠포드에서 개발한 Global Vectors for Word Representation.
빈도기반의 DTM에서 차원을 줄인 LSA 방식 + 예측방식
하지만 성능이 떨어져서 잘 안쓴다.
(LSA : DTM에 특잇값 분해를 사용하여 잠재된 의미를 이끌어내는 방법론)
2023.02.18 - [DL/NLP] - 벡터화 발전과정 (BoW/DTM/TF-IDF/SVD/LSA/LDA/토픽모델링)
'Study (Data Science) > NLP' 카테고리의 다른 글
| 모델 발전과정 2 - Attention (Bahdanau / Luong) (0) | 2023.02.28 |
|---|---|
| 모델 발전과정 1 - SLM / NNLM / RNN / Seq2seq (0) | 2023.02.27 |
| 벡터화 발전과정 3 - 임베딩 (Embbeding) / Sparse - Dense - Embedding vector (0) | 2023.02.22 |
| 토큰화 / 인덱싱 / 벡터화 / 임베딩 (0) | 2023.02.22 |
| 벡터화 발전과정 2 - soynlp (비지도학습 한국어 형태소 분석기) (0) | 2023.02.20 |



댓글