잠깐! 잊어버리니깐, 다시 한 번 더..
트랜스포머 모델이란?
Encoder는 input sequence를 continuous한 representation으로 바꾸고,
Decoder는 이 representation을 output sequence로 바꾼다.
최종 Output은 Probability가 나옴!
먼저
0. Inputs을 embedding 후 positional encoding 하고
1. Encoder 돌리고 x 6번
- Multi-Head Attention
- 잔차 Add + Normalization
- ----------------
- FFW layer
- 잔차 Add + Normalization
2. Decoder 돌리고 x 6번
- Masked - Multi-Head Attention (현재 위치보다 더 뒤에 있는 단어는 보지 못하도록 가리는 용도)
- 잔차 Add + Normalization
- ----------------
- Encoder의 output 받은 것과, Decoder앞에서 받은 값을 같이 Multi-Head Attention
- 잔차 Add + Normalization
- ----------------
- FFW layer
- 잔차 Add + Normalization
Multi-Head Attention 을 이루는 두 가지 레이어
- Scaled Dot-Product Attention (3가지 출현함)
- Encoder에서의 순정
- Decoder에서의 마스크
- Decoder에서의 짬뽕
- Linear Layer

Multi-Head Attention
밑에나오는 self-attention은 전체 dimension(=임베딩차원수, 단어 하나당 표현의 깊이)에게 하나의 어텐션만 적용시킨 것이고, 멀티헤드는 전체 dimension/ h (head갯수) 를 나누어 attention을 h번 적용시키는 것이다.
논문에서는 dimension = 512, h = 8 이어서,
64개 차원에 헤드 하나씩 (어텐션도 하나씩) 을 사용한 것이다.
그렇다면 왜 굳이 multi-head를 하였는가?
정보의 손실 없이 더 잘 얻기 위해서이다.
(바나나라는 단어가 512차원의 Embedding을 가진다고 가정합시다. 그중 64차원은 노란색에 대한 정보를 표현하고, 다른 64차원은 달콤한 맛에 대한 정보를 표현할 겁니다. 같은 맥락으로 바나나의 형태, 가격, 유통기한까지 모두 표현될 수 있겠죠. 저자들은 '이 모든 정보들을 섞어서 처리하지 말고, 여러 개의 Head로 나누어 처리하면 Embedding의 다양한 정보를 캐치할 수 있지 않을까?' 라는 아이디어를 제시합니다. - Aiffel lms)
만약 단어 10개의 한 문장이 있다면,
임베딩 후의 쉐잎이 (10,512) 인데,
이를 8개 헤드로 나누면 (10,64) X 8이 되는 것이고,
64차원당 하나의 독립적인 attention이
(한번에 처리할 문장갯수, 단어갯수, V벡터의 차원수)
(batch_size, seq_length, d_v) x (num_heads) 만큼 뽑힌다. (d_v: V의 차원수)
이것을 마지막에 concat하게 되면 shape이 (batch_size, seq_length, num_heads * d_v) 인 텐서가 된다.
하지만 쪼개진 64차원이 연관 있는 차원들끼리 묶여있진 않을 수 있지 않은가?
그래서 그 앞단에 Linear 레이어를 통과시켰다.
Linear 레이어는 데이터를 특정 분포로 매핑 시키는 역할을 해주기 때문에, 설령 단어들의 분포가 제각각이더라도 Linear 레이어는 Multi-Head Attention이 잘 동작할 수 있는 적합한 공간으로 Embedding을 매핑할 수 있다.



Scaled Dot-Product Attention (기본개념)

Attention (Q, K, V) = W 에 대해 잠시 살펴보면,
이들은 모두 입력 시퀀스 내의 임베딩 벡터이다.
이들 벡터들은 서로 다른 매개 변수로 구성된 매트릭스(행렬) 형태로 저장된다.
이들의 Shape은 공통적으로 (미니배치크기, 문장의 길이, 각 Q,K,V 벡터의 차원) 이 되고,
미니배치크기는 한번에 처리로 들어갈 문장 갯수,
문장의 길이는 len(sentence)이기 때문에 단어 갯수가 된다.
논문에서는 각 벡터의 차원 (d_k, d_q, d_v) = 64이다.
이는 임베딩 차원과는 개념이 다르다. 논문에서의 임베딩 차원은 512이다.
임베딩차원과 벡터의 차원은 모두 하이퍼파라미터이다.
- Query(Q) : 현재 처리하려는 입력시퀀스의 위치정보가 있음. 이 벡터를 기반으로 다른 위치들과의 관련성을 측정.
- Key(K) : 모든 입력시퀀스의 위치정보가 있음. Query 벡터와의 유사도 측정에 사용됨.
- Value(V) : 입력 시퀀스 내의 각 위치에 대한 정보를 담고 있는 벡터. Key와 담은 정보가 같아보이지만, 가중치와 곱하기 위해서 만든 것으로 용도가 다르고, 값도 다를 수도 있음. Key는 Query와 상관이 있고, Value는 Weight를 곱해서 output을 내기 위함이다.
- 인코더에서는 K와 V가 같은 정보를 담고 있음. 내부표현이 같음.
- 하지만 디코더에서는 인코더의 출력정보가 첨가되어 있어서 값이 다를 수 있음.
- Output = Weights x V
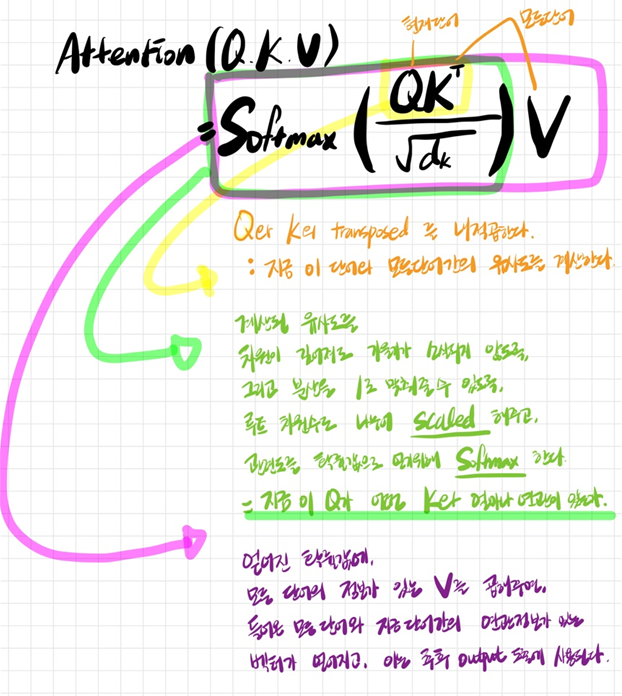
- = Softmax(Q x K(전치)) X V
- Attention Score = scaled Dot-Product = Q와 K를 내적곱한 확률값인 attention이 scaled 되었다는 의미
- 현재 처리하려는 입력시퀀스가 모든 단어들 중 어떤 단어와 관련되어 있는지 찾기 위해서 현재 나의 상태 Q에 전체의 상태 K를 Transpose 하여 내적곱하고,확률적으로 어떤 것과 가장 관련성이 높을지 비교해 볼 수 있도록 softmax를 통해 확률값으로 바꿔준다. (Dot-Product)
- 그리고 차원 수가 깊어짐에 따라 Softmax 값이 작아지는 것을 방지하기 위해 분산을 1로 맞춰주는 scaling을 하려고 루트 차원수로 나눠준다. (Scaled)
1. Scaled Dot-Product Attention (순정)
- 모델 내 위치 : Encoder
- Q : 이전 layer의 output tensor
- K : 이전 layer의 output tensor
- V : 이전 layer의 output tensor.
- Q,K,V 모두 output 시퀀스들 모든 위치의 정보를 포함하고 있음 (Q, K, V의 출처가 모두 동일)
2. Scaled Dot-Product Attention (마스크)
- 모델 내 위치 : Decoder
- Q : 이전 layer의 output tensor
- K : 이전 layer의 output tensor
- V : 이전 layer의 output tensor.
- Q,K,V 모두 output 모든 위치가 아니라, 자신의 위치 앞까지의 정보만 포함하고 있음 (Q, K, V의 출처가 모두 동일)
3. Scaled Dot-Product Attention (짬뽕) - 요기서 다음 단어가 생성됨
- 모델 내 위치 : Decoder
- Q : Decoder의 이전 layer output tensor (현재 디코더의 단어)
- K : Encoder의 output tensor (이전까지 출력된 인코더의 모든단어)
- V : Encoder의 output tensor
- 현재 디코더에서 처리 중인 단어와 인코더에서 출력된 모든 단어들 사이의 관계를 측정하여, 현재 디코더 단어와 가장 유사한 단어를 찾아내게 된다. softmax로 도출된 확률값으로 현재단어와 가아아아장 유사한 인코더 단어를 선택하여 이를 기반으로 다음 단어를 생성한다.

인과관계 마스킹 (Causality Masking)
seq2seq 모델에서는 Decoder의 <start>토큰만으로 자신이 가진 context vector값을 이용해 그 다음 단어를 만들어야 하는 자기회귀(Autoregressive) 방법을 사용했다. 하지만 transformer는 병렬구조로 처리해버려서 그 앞단의 정보들이 축적되어 어 쌓여 전달되지 않아 자기회귀가 힘들다. 그래서 마스킹이 나왔다.
인과관계 마스킹의 목적은, 문장의 일부를 가려 인위적으로 연속성을 학습하게 하는 방법이다.
마스킹 된 부분은 - 무한대를, 마스킹 되지 않은 부분은 0 으로 요소를 채운 행렬을 기존 행렬에 더하고 softmax를 하게 되는데, softmax는 값이 큰 것에 큰 확률값을 주기 때문에, 마스킹된 부분은 - 무한대를 더하게되어 0에 수렴하게 된다. 그러면 자연스럽게 마스킹되지 않은 부분들이 적절한 확률값을 가지게 되고, 지금 현시점 전까지의 단어로만 다음 단어를 생성하는 의사결정이 가능하게 된다.


Position-wise Feed-Forward Networks
활성화함수 ReLU를 통과시켜주기 위한 FC layer.
입력 시퀀스에서 각 위치정보를 인코딩 받은 것을 모델이 더 효과적으로 처리할 수 있도록 값을 활성화해줌.
FC이긴 하지만 각 위치(position) 별로 독립적으로 적용해주므로써, 위치마다 다른 연산이 수행되게 해줄 수 있음.
그래서 position-wise라고 불리게 되었음.
각 위치에서 동일한 연산을 하는 RNN과 가장 큰 차이점.
트랜스포머의 FFN에는 Dense가 두 층 있음
d_ff는 두개의 fc layer의 hidden size를 나타내는 하이퍼파라미터로, 너무 높으면 너무 복잡해짐.
보통 d_model * 2 이상을 쓰므로,
d_model이 512 이니, d_ff = 1024 ~ 2048 정도를 통상 사용함.
논문에서 d_ff = 2048, d_model = 512 이고,
w_1이 2048차원으로 매핑 후 ReLU 하면,
w_2가 512차원으로 되돌릴꺼임.
class PoswiseFeedForwardNet(tf.keras.layers.Layer):
def __init__(self, d_model, d_ff):
super(PoswiseFeedForwardNet, self).__init__()
self.w_1 = tf.keras.layers.Dense(d_ff, activation='relu')
self.w_2 = tf.keras.layers.Dense(d_model)
def call(self, x):
out = self.w_1(x) # x 텐서를 w_1 layer에 넣고,
out = self.w_2(out) # w_1텐서에서 나온 값을 w_2 layer에 넣어라
return out

이렇게 마치면,,
내가 그린 Transformer의 최종 모형은 이렇다.

'Study (Data Science) > NLP' 카테고리의 다른 글
| Transformer 4 - GPT / BERT / 그 외 파생모델들 (0) | 2023.03.14 |
|---|---|
| Transformer 3 - Residential Add / Normalization (0) | 2023.03.14 |
| Transformer 1 - Positional Encoding (0) | 2023.03.09 |
| 모델 발전과정 3 - GNMT (Google's Seq2seq 8 layers w. Residual) (0) | 2023.02.28 |
| 모델 발전과정 2 - Attention (Bahdanau / Luong) (0) | 2023.02.28 |



댓글