
Dataset
400 seat theatre that hosted multiple viewings of multiple movies over a twelve month period
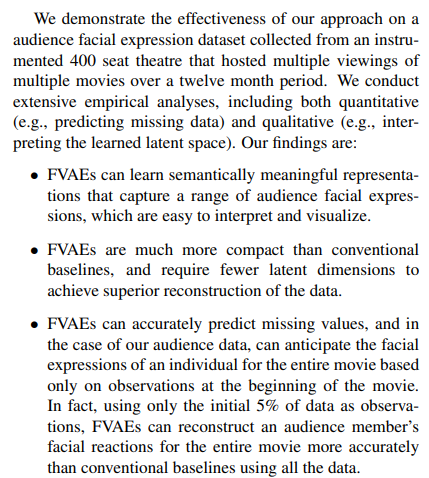
Modeling

stage 1. TF
MF (Matrix Factorization)은 원래 linear layer.
하지만 이를 VAE (Variational Autoencoder)를 사용해 non-linear로 바꿔 latent value를 갖게 했음.
행렬분해 variable def.
N -> U user
T(time) -> V
D(136) -> F



Stage 2. Non-linear TF (using VAE)
TF를 NLTF로 바꾸면서
Ui는 로그태우고 베이지안.. 아마 표정이 영상으로 분석되지 않는 부분을 개선하기 위해서가 아닐까.
V도 베이지안해서 정규분포화 한 후에 f세터로 딥러닝 태웠음
DL은 보통 다 MLE로 최적화하지만 여기서는 MAP를 채택. 관련자료 하기와 같음.
https://kolazzing.com/entry/MLE-MAP-prior-posterior-likelihood
MLE, MAP / prior, posterior, likelihood
베이지안 머신러닝 모델 모델 파라미터를 고정된 값이 아닌 불확실성(uncertainty)을 가진 확률 변수로 보는 것, 데이터를 관찰하면서 업데이트되는 값으로 보는 것 베이즈 정리(Bayes' theorem) prior(pri
kolazzing.com

Stage 3. Collaboration (FVAE)

linear인 MF의 한계를 중간에 VAE를 넣어 분포추정이 가능하게 만들었다.
신경망을 이용할 때에 MLE 보단 MAP를 사용해서 영상에서 잡히지 않는 부분을 컨트롤했음




댓글