희소 표현(Sparse Representation)
단어 벡터의 각 차원마다 고유의 의미를 부여하는 방식 (너무 양이 많아 결국 한계가 옴)
분산 표현(Distributed Representation)
유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다 라는 분포가설에서 비롯하여, 유사한 맥락에 나타난 단어들끼리는 두 단어 벡터 사이의 거리를 가깝게 하고, 그렇지 않은 단어들끼리는 멀어지도록 조금씩 조정
Embedding layer
- 컴퓨터용 단어사전을 만드는 곳 (단어 n개 쓸꺼고 k 깊이(차원)로 표현한 것)
- Weight이다
- Lookup Table이다 (LUT : 주어진 연산에 대해 미리 계산된 결과들의 집합(배열), 매번 계산하는 시간보다 더 빠르게 값을 취득해 갈 수 있도록 사용되는 레퍼런스로 사용하는것)
- NLP에서는 CV처럼 분산이 되지 않아 어떤 연산결과를 embedding layer에 연결시키는 것은 불가능하다. (입력에 직접 연결해줘야 함)
- (예전필기)
# NLP의 첫번째 레이어
# 사용할 문장에서 사용할 단어'만' 벡터로 만드는 작업.
# 실수(소수점)으로 되어있고, weight같은 기능을 하며, 원핫인코딩같은 역할이다.
# 만약 단어가 100개고, 쓸 단어가 10개라면,
# 원핫일때는 단어 하나하나 100개 모두 원핫코딩하여 숫자로 변환해야하지만
# 임베딩일때는 쓸 10개만 실수로 전환하여 숫자로 변환하고, 의미별로 나누기때문에
# 시간이 훨씬 적게 걸리고 빠르다. - embedding으로 사용될 단어들을 LUT로 만들어 놓고, 분석시킬 문장을 one-hot하여 그 문장에 있는 단어를 LUT에서 찾아 해당값들만 output으로 내어놓음
RNN 주요 레이어 종류 (문장특화 layer들, 세개 모두 호환가능)
1) SimpleRNN :가장 간단한 형태의 RNN레이어, 활성화 함수로 tanh가 사용됨(tanh: -1 ~ 1 사이의 값을 반환)
2) LSTM(Long short Term Memory) : 입력 데이터와 출력 사이의 거리가 멀어질수로 연관 관계가 적어진다(Long Term Dependency,장기의존성 문제), LSTM은 장기 의존성 문제를 해결하기 위해 출력값외에 셀상태(cell state)값을 출력함, 활성화 함수로 tanh외에 sigmoid가 사용됨
3) GRU(Gated Recurent Unit) : 뉴욕대 조경현 교수 등이 제안, LSTM보다 구조가 간단하고 성능이 우수함
RNN (Recurrent Layer)
- 문장, 영상, 음성 등 순차적(sequential)한 데이터의 순차적 특징을 반영할 수 있음)
- 한계 : 하나의 weight를 시간적 흐름에 따라 단계별로 계속 업데이트하다 보니 기울기가 소실되는 (힘을 실어야 할 곳에 힘을 주지 못하는) 일이 벌어지기도 함. (기울기 소실 :Vanishing Gradient) 기울기가 소실되다 보니 문장이 길어질 수록 데이터 앞쪽의 정보가 데이터 뒤쪽까지 전달이 잘 되지 않는 장기의존성(Long-Term Dependency)문제가 있음
- 보통 양방향 (Bidirectional)을 사용 : 일단 문장 전체를 끝까지 분석한 후(순방향), 번역(역방향) 언어는 끝까지 들어봐야 아는 경우가 많기 때문에.
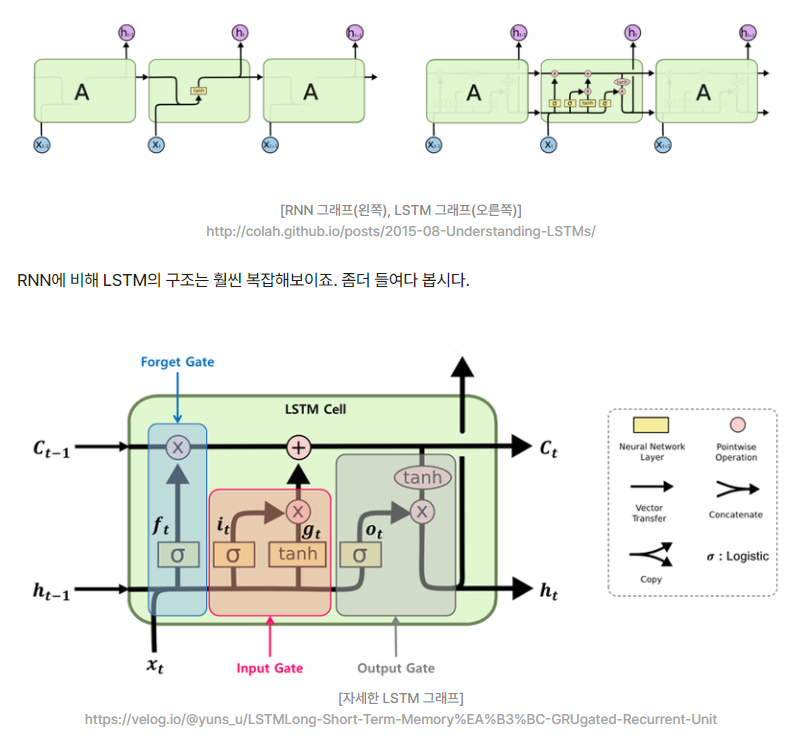
LSTM (Long Short - Term Memory)
- 장기의존성 문제를 해결한 RNN 레이어
- 이름그대로 장기기억과 단기기억을 구분하여 해결함.
- RNN에서 없었던 Ct (Cell state)가 핵심. 전체 체인을 관통해 흐르면 장기기억의 역할을 수행하여 데이터 앞쪽의 정보를 뒤까지 전달.
- 지우고, 쓰고, RNN 참고하고.
- Weight가 4배로 늘어남.
Ct라는 메모지에
f : forget : 지우고
i,g : input x gate? : 쓰고
o : output : 기존 RNN으로 가져온 것 참조하여 결과 내놓음
GRU (Gated Recurrent Unit)

r : reset : 과거의 정보를 적당히 리셋하고u : update : 최신정보를 업데이트하고 c : candidate : 현시점의 후보를 결정LSTM과 목적과 성능이 거의 비슷하지만, 학습할 w가 적다는 이점이 있음. (LSTM의 1/4) 적은 데이터에도 학습성능이 잘나옴
'Study (Data Science) > NLP' 카테고리의 다른 글
| 벡터화 발전과정 (BoW/DTM/TF-IDF/SVD/LSA/LDA/토픽모델링) (0) | 2023.02.18 |
|---|---|
| Keras Tokenizer 와 SentencePiece 비교 이해 (0) | 2023.02.15 |
| 전처리, 분산표현, 임베딩, 토큰화 (0) | 2023.02.14 |
| Chatbot (0) | 2023.01.27 |
| Ex12_ NLP / 뉴스 요약봇 (0) | 2023.01.25 |



댓글