1. 데이터 전처리
- null값 제거 : .nunique()로 null 확인 후, .dropna로 제거
- 중복 제거 : drop_duplicates()로 제거
- 텍스트 정규화와 stopwords 제거
- 정규화사전, 불용어사전(NLTK) 를 불러오거나 만들어주거나 한 후에
- preprocess_sentence라고 함수를 만드는데
- text 컬럼은 정규화와 불용어 모두 처리하고, clean_text=[ ]에 담고
- headlines 컬럼은 자연스러운 문맥을 위해 정규화만 하고, clean_healines =[ ] 에 담아둠.
2. train, test 나누기
- 최대길이 정하기
- 길이분포를 구하여 그래프로도 한번 보고
- 적당한 text_max_len, headlines_max_len을 임의로 잡는데,
- 잡을 때 평균보다는 약간 높게 하여 80-85%정도 포함되게 잡도록
- 전체의 몇 %나 되는지 계산도 해보고
- 각각의 max_len이 안되면 데이터에서 제외되도록 apply.lambda 로 정리
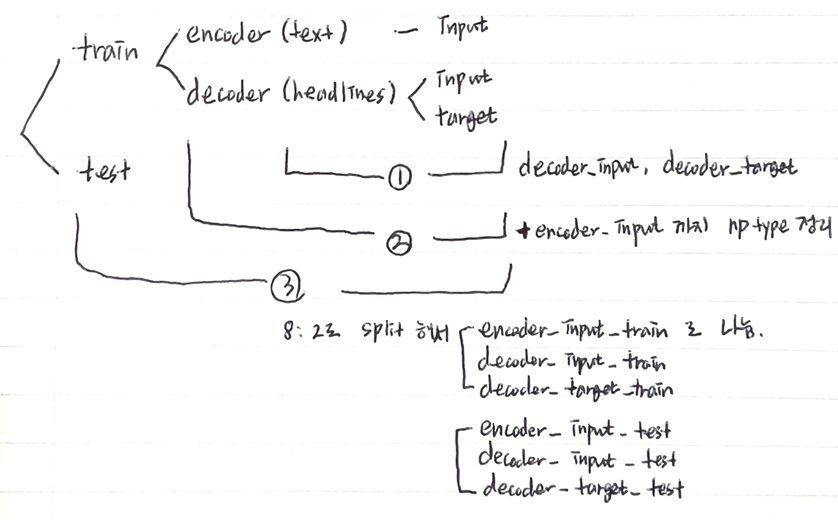
- train, test 나누기
- headlines를 eos, sos 추가하여 decoder_input, decoder_target 나누고
- decoder_input, decoder_target + encoder_input까지 Numpy로 형식 바꾸고
- 8:2로 train, test 나누기위해
- encoder_input과 같은 크기와 형태의 0으로만 이루어진 정수 시퀀스를 하나 만들고,
- 이 시퀀스를 shuffle 하고,
- 그 idx에 data를 maping 하여 randomly ordered한 상태에서
- 8:2로 슬라이싱하여 최종 6개의 데이터셋으로 준비
- 정수인코딩
- 토큰화 > 단어사전 > 정수인코딩 ((encoder / decoder) 따로해주기)
- train 으로만 희귀단어 조사하여 단어장 크기값 정하기
- tokenizer 선언
- fit_on_texts로 숫자매핑 (encoder_input_traiin)/(decoder_input_train)
- threshold 임의값 정해서 희귀단어가 얼마나 되는지 조사하고
- 희귀단어 제외하면 단어가 얼마정도 남는지 보고, 이를 기준으로 단어장크기를 정해야함.
- train, test 모두, 총 6개의 데이터셋 모두 시퀀스화하기
- tokenizer 선언
- 바로 texts_to_sequences(6개 데이터셋) 모두 실행하여 시퀀스화함.
- train 으로만 희귀단어 조사하여 단어장 크기값 정하기
- 토큰화 > 단어사전 > 정수인코딩 ((encoder / decoder) 따로해주기)
- 최종 데이터셋 6개 정리하기
- 희귀단어 제외 후에 생긴 null값 제거하기
- 패딩하기 (post)
3. 모델설계
- Encoder
- embedding_dim, hidden_size 주고
- encoder_input(text_max_len, )로 주고
- Embedding(단어장크기, emd_dim)로 임베딩 레이어
- LSTM 1,2,3 쌓고, state는 받아서 2-5로 넣음
- Decoder
- decoder_input(None. )로 주고
- Embedding(단어장크기, emd_dim)로 임베딩 주고
- Embedding 하나더! decoder_input 넣어주고
- LSTM 1 쌓고
- decoder_outputs, _, _로 encoder state 넣고
- 출력층은 softmax로
- Attention 메커니즘 : 인코더와 디코더의 모든 time step의 hidden state를 어텐션 층에 전달하고 결과를 리턴
- AddictiveAttintion으로 어텐션 함수 선언
- 모든 time_step의 hidden state 받는 attn_out 만들고
- concat으로 en, de의 hidden state들을 다 연결하고
- 2-6 softmax 출력층에 넣어줌
4. 모델훈련
- compile : optimizer - rmsprop / loss - sparse categorical crossentropy / earlystop 주고
- fit
- x : encoder_input_train, decoder_input_train / y : decoder_target train
- val x : encoder_input_test, decoder_input_test / y : decoder_target test
5. 인퍼런스(추론) 모델 구현 (다음 단어를 예측하여 뱉어내는 모델)
- 정수 -> 문자로 바꿀 수 있도록 함수 미리 준비하고
- 답이 없기 때문에 eos 나올때까지 디코더를 time step마다 반복적으로 돌려야 하므로, 따로 설계함
- 다시 돌리면서 state는 다 저장하는 인코더 설계하고
- 어텐션 사용해 출력하는 디코더 설계하고
- 인퍼런스 단계에서 eos나올 때 까지 단어 시퀀스를 완성하는 함수를 만들어 줌.
6. 모델 테스트 (추상적 요약)
- 원문의 정수 시퀀스 -> 텍스트 시퀀스로 변환하는 함수와 (text)
- 요약문의 정수 시퀀스 -> 텍스트 시퀀스로 변환하는 함수 만들고, (headlines)
- for문으로 돌려 비교해봄
7. 추출적 요약 실행해서 비교
- 추출적 요약은 추상적처럼 새로운 단어를 생성해내는게 아니라 그냥 추출만 해냄
- summ.summarizer 모듈의 summarize 함수 사용함
728x90
'Study (Data Science) > NLP' 카테고리의 다른 글
| 벡터화 발전과정 (BoW/DTM/TF-IDF/SVD/LSA/LDA/토픽모델링) (0) | 2023.02.18 |
|---|---|
| Keras Tokenizer 와 SentencePiece 비교 이해 (0) | 2023.02.15 |
| 전처리, 분산표현, 임베딩, 토큰화 (0) | 2023.02.14 |
| Chatbot (0) | 2023.01.27 |
| NLP 기본개념 (0) | 2022.12.29 |



댓글