Soynlp
- 품사 태깅, 형태소 분석 등을 지원하는 한국어 형태소 분석기.
- 비지도 학습으로 데이터에 자주 등장하는 단어들을 형태소로 분석함.
- 내부에 단어사전 같은
단어 점수표를 만들어 동작하며 . 이 점수는 응집 확률(cohesion probability) 과 브랜칭 엔트로피(branching entropy) 를 활용함.
- 학습은 txt string (말뭉치, 진짜뭉치)을 DoublespaceLineCorpus로 띄어쓰기 두개 기준으로 떼어내 문서단위로 구분하고, 이를 WordExtractor로 단어를 추출하여 .train 시키면, 단어점수표가 만들어짐.
단어점수표 구조
응집 확률 (cohesion probability)
- 내부 문자열(subword)가 "얼마나 응집"하여 "자주" 등장하는가의 척도.
- 문자열을 문자 단위로 분리하여 내부 문자열을 만드는 과정에서, 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그다음 문자가 나올 확률을 계산하여 누적 곱을 한 값.
- 값이 높을수록 전체 코퍼스에서 이 문자열 시퀀스는 하나의 단어로 등장할 가능성이 높음



브랜칭 엔트로피(branching entropy)
- 주어진 문자 시퀀스에서 다음 문자 예측을 위해 헷갈리는 정도. (헷갈리는 정도 = 엔트로피값)
- 하나의 완성된 단어에 가까워질 수록 문맥으로 인해 정확히 예측할 수 있게 되므로, 브랜칭 엔트로피값은 점차 줄어듬.

이런 단어점수표를 근간으로, soynlp는 여러가지 토크나이저를 제공하고 있음.
토크나이저 종류
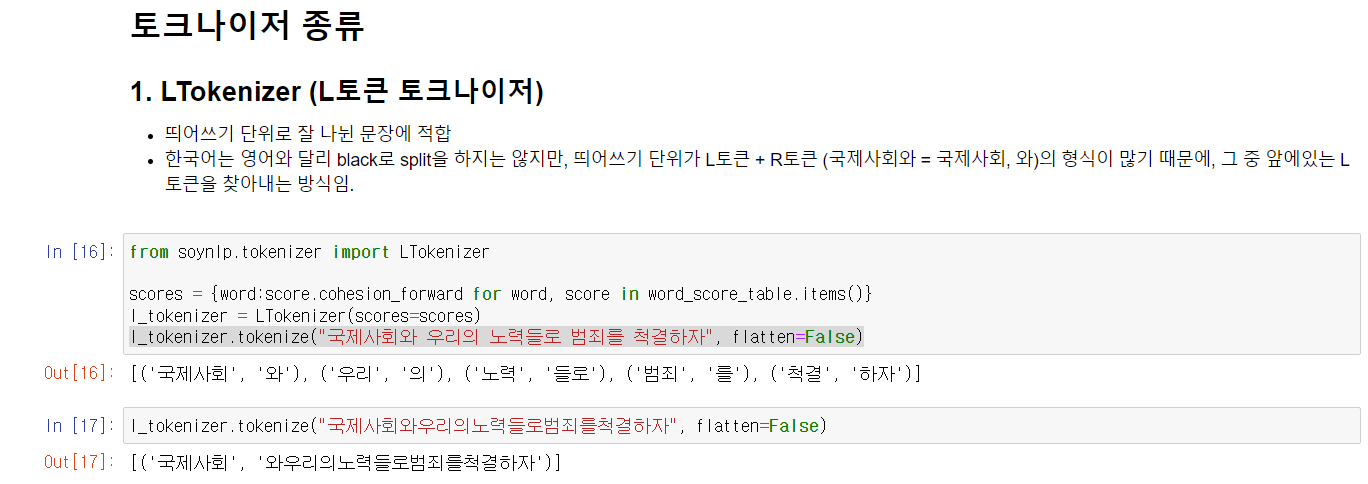
LTokenizer (L토큰 기준)
- 띄어쓰기 단위로 잘 나뉜 문장에 적합
- 한국어는 영어와 달리 black로 split을 하지는 않지만, 띄어쓰기 단위가 L토큰 + R토큰 (국제사회와 = 국제사회, 와)의 형식이 많기 때문에, 그 중 앞에있는 L토큰을 찾아내는 방식임.
MaxScoreTokenizer (최대점수 기준)
- 띄어쓰기 안된 문장에 적합
- 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저.

728x90
'Study (Data Science) > NLP' 카테고리의 다른 글
| 벡터화 발전과정 3 - 임베딩 (Embbeding) / Sparse - Dense - Embedding vector (0) | 2023.02.22 |
|---|---|
| 토큰화 / 인덱싱 / 벡터화 / 임베딩 (0) | 2023.02.22 |
| 벡터화 발전과정 (BoW/DTM/TF-IDF/SVD/LSA/LDA/토픽모델링) (0) | 2023.02.18 |
| Keras Tokenizer 와 SentencePiece 비교 이해 (0) | 2023.02.15 |
| 전처리, 분산표현, 임베딩, 토큰화 (0) | 2023.02.14 |



댓글