Regression
두시간 반을 갈아넣어 만든 표..... ㅠㅠㅠㅠㅠ
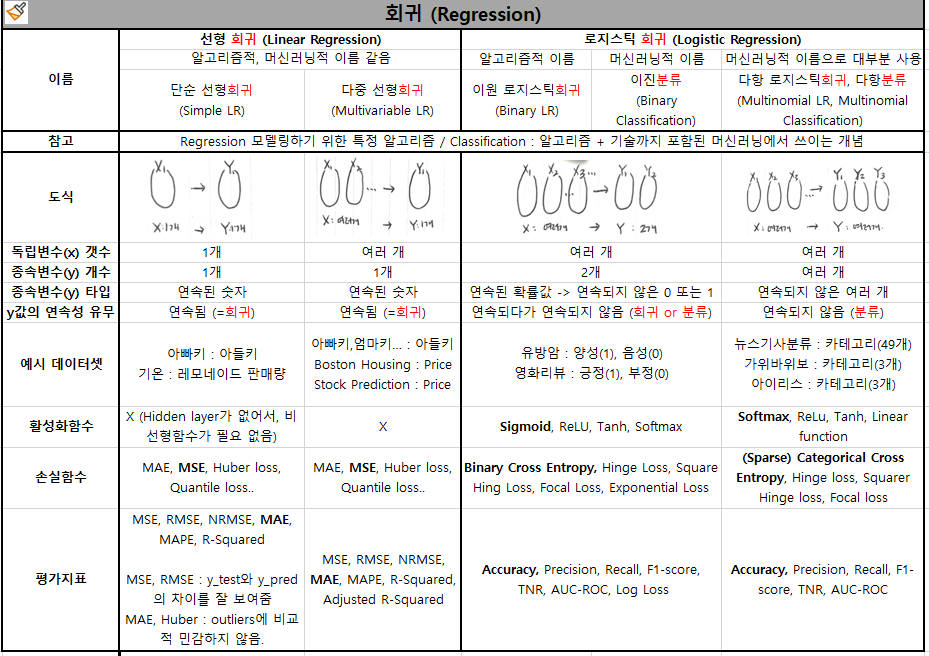
선형 회귀 분석(Linear Regression)
1. 표기법


- 종속변수 Y와 한 개 이상의 독립변수 X와의 선형 상관관계를 모델링하는 회귀분석 기법
- 주어진 데이터에 우리의 선형 식이 잘 맞도록 회귀계수 및 오차를 구하는 것
- 회귀계수 = weight / : 종속 변수와 독립 변수 사이에 오차 = bias
- 수학과의 차이는, W, b는 단순스칼라 값이 아니라 행렬로 거의 대부분 오게됨
2. 용어설명
- 잔차(residual)
- 관측값(y_test)과 회귀직선의 예측값(y_pred)과의 차이, 보통 e로 표기
- 잔차로 그래프를 그린 후에 특정 패턴이 나타나면 회귀직선이 적합하지 않다는 의미.
- 잔차의 개념을 잘 알면 손실함수를 이해할 수 있음
- 손실함수의 대표적인 최소제곱법
- n개의 점 데이터에 대한 잔차의 제곱의 합을 최소로 하는 W, b를 구하는 방법
3. 평가지표
- 회귀모델이 잘 결정되엇는지 확인할 때 참고하는 지표
- 결정계수(R-squared 또는 R2 score) : 0-1 사이의 값, 1에 가까울수록 해당 회귀모델이 잘 결정되었다는 뜻.
4. R2 score

- SSR : Y의 평균값과 예측값의 차 제곱
- SST : Y의 평균값과 실제값의 차 제곱
- R2 score는 0~1사이의 값
- 해석
- 1 : 예측값과 실제값이 같다. 예측이 아주 잘된다. 독립변수로 종속변수를 예측했는데 실제값과 같다. 독립변수가 적절하다.
- 0 : SSR이 0이다. 예측값과 평균이 같다는 뜻. 컴터가 예측은 안하고 그냥 예측치를 평균치로 찍었다. 독립변수가 부적절하다.
5. 선형 회귀분석 심화이해
- 선형 회귀분석의 기본 가정
- 선형성
- 여러개의 독립변수중 종속변수 간에 선형성이 있는 변수를 잘 선택해야 한다.
- (p-value로 변수선택법 참고하여 잘 선택하기)
- 독립성
- 다중 회귀분석(x변수가 2개이상) 에만 해당
- x 간에 상관관계가 없이 독립적이어야 한다는 뜻
- (다중공선성제거. 변수선택법 stepwise로 해결가능)
- 등분산성
- 분산이 같다는 것이고, 분산이 같다는 것은 특정한 패턴 없이 고르게 분포했다는 의미
- 등분산성의 주체는 잔차
- 정규성
- 잔차가 정규성, 즉 정규분포를 띄는지 여부를 의미
- Shapiro-Wilk Test로 확인 가능
- 선형성
변수 선택법 참고할 블로그 글
https://blog.naver.com/PostView.nhn?blogId=jaehong7719&logNo=221909615639
머신러닝 기초 4 - 변수선택법(전진선택법, 후진소거법, 단계적선택법)
지난 포스팅에 이어 본격적으로 변수선택법에 대해 알아보겠습니다. 데이터분석에서 변수선택법은 변수가 ...
blog.naver.com
로지스틱 회귀분석(Logistic Regression)
1. 정의
- 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해 주는 지도 학습 알고리즘
- 특정 threshold 값을 기준으로 삼아서 예측된 확률 값이 threshold 이상인 것과 미만인 것으로 분류를 하는 식
- 1개 이상의 독립변수가 있을 때 이를 이용하여 데이터가 2개의 범주 중 하나에 속하도록 결정하는 이진 분류(binary classification) 문제를 풀 때 로지스틱 회귀분석을 많이 사용
2. 표기법

- Odds : 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값
- Odd 구하는 공식 = 사건이 발생할 확률 / (1 - 사건이 발생할확률) = 유방암 걸릴확률이 0.2 라면, 0.2/0.8 = 0.25
- 이 odd에 log를 한 log-odd를 선형 회귀변수의 종속변수로 가정하고 구하면 됨. = 각 컬럼들이 독립변수 x가 되고 log-odd 가 종속변수 y값이라고 생각하면 됨
- 우리가 필요한 것은 종속변수가 0일 확률인 y=0∣x 가 필요하므로 다시 정리하면,


- 결국 sigmoid 식과 같아짐

3. 계산단계
- 실제 데이터를 대입하여 Odds 및 회귀계수를 구한다.
- Log-odds를 계산한 후, 이를 sigmoid function의 입력으로 넣어서 특정 범주에 속할 확률 값을 계산한다.
- 설정한 threshold에 맞추어 설정값 이상이면 1, 이하면 0으로 이진 분류를 수행한다.
그렇다면, 로지스틱 회귀는 이진분류이니 회귀가 아니라 분류 아닌가?
로지스틱 회귀는 수학적, 알고리즘적으로는 회귀가 맞다.
왜나하면 모델이 리턴하는 값이 확률값, 즉, 연속된 값이기 때문에 회귀모델이 맞다.
하지만 엄밀히는 여기까지만 회귀이다.
마지막에는 임계치에 따라 argmax로 0과 1 둘 중 하나로 출력은 하며, 이는 회귀모델의 응용과정이지만, 0 or 1로 값이 연속되지는 않기 때문에 이 부분부터는 엄연히 구분하면 classification 이다. 그러나 이 과정은 회귀모델의 응용 과정에 불과하므로, 총체적으로 회귀로 분석하는 것이 대부분이다.
하지만 머신러닝적으로 보면 이진분류이다.
GPT에게 물어본 결과로는, regression과 classification을 구분해 내었고, 답안은 하기와 같다.
머신러닝이란 것 자체가 알고리즘에 기술이 더해진 형태인지라 regression이라는 것 자체가 모델링을 위한 하나의 알고리즘의 명칭이고, 이 알고리즘에 argmax라는 기술을 더해져 classification이라는 머신러닝 모델로 구분, 혼용하고 있는 것 같다. 다만 다항분류의 경우는 논란의 여지 없이 classification이다.
Binary logistic regression and binary classification are two related but distinct concepts in machine learning.
Binary logistic regression is a type of generalized linear model that is used to model the relationship between a binary outcome variable and one or more predictor variables. The goal of binary logistic regression is to fit a model that can predict the probability of the outcome variable being one of two possible values (e.g. 0 or 1), based on the values of the predictor variables. In order to model the probability of a binary outcome, logistic regression uses the logistic function, which maps the linear combination of the inputs and weights to a value between 0 and 1.
Binary classification, on the other hand, is a broader concept that refers to any machine learning problem where the goal is to predict one of two possible outcomes, based on a set of input features. Logistic regression is just one of the many algorithms that can be used for binary classification, others include decision tree, Random Forest, SVM, and many more.
So, the main difference between binary logistic regression and binary classification is that binary logistic regression is a specific type of algorithm for modeling binary outcomes, whereas binary classification is a broader concept that encompasses a wide range of algorithms and techniques. Logistic regression is a type of algorithm that is commonly used in binary classification problems when the goal is to predict a probability of an outcome, while other binary classifiers can be used when the goal is to predict a class label directly.
'Study (Data Science) > DL' 카테고리의 다른 글
| 확률과 통계 (0) | 2023.01.16 |
|---|---|
| Entropy / Cross - Entropy (0) | 2023.01.12 |
| Regularization, Normalization (0) | 2023.01.11 |
| model.summary 에서의 param# 구하기 (0) | 2023.01.06 |
| 활성화함수 종류 (0) | 2022.12.29 |



댓글