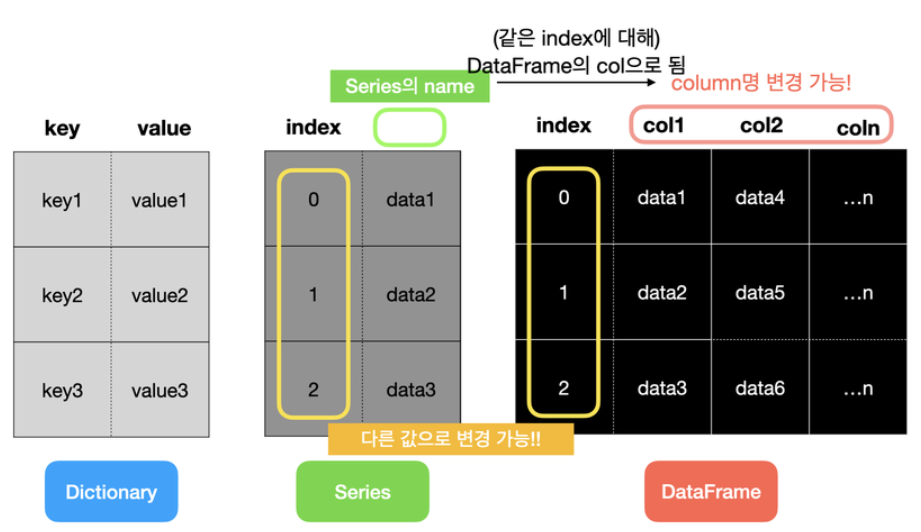
Dictionary : {키 : 값}
키, 값 둘 다 정보를 바꿀 수는 있지만 인덱스를 먹일 수 없음.
Series : {인덱스 : 값}
둘 다 변경 가능하고, 인덱스가 키값처럼 정보를 담을 수도 있지만, 정리가 깔끔하지 않음
DataFrame :
index 와 column으로 그 제목을 따로하며 수정가능하고, 그 안에 값들을 담음. 정리된 데이터셋
정보 확인
- df = pd. read_csv(csv_path or file name) : 불러오기
- df.columns : column 이름들이 list로 나옴
- df.dtypes : 데이터 개별 값의 자료 형태 (int, str, object 등등),카테고리가 아닌 데이터는 꼭 해보기
- df.info() : 자료형과 null 있는지 보여줌
- df.describe() : 기술 통계량 (데이터 갯수, mean값, std, min, 25% 등등)
- df.head() or tail() : 위, 아래 5줄. () 안에 숫자넣으면 불러올 행 수 지정 가능
null 확인
- df.isnull().sum() : 결측값 (값이 없는것) 총 몇개인지 콜롬별로 보여줌
- len(df) - df.count() : 열별로 null 값이 몇개인지 count 하여 보여줌
- df['Publisher']=df['Publisher'].fillna('None') : Publisher 열에 null 값을 None 이라고 채워 Publisher 행으로 저장
drop 하기
- df = df.drop('Year',axis=1)
- df.drop(['열이름'.'열이름'],axis=1)
합치기
- pd.concat([df1, df2]) : concat은 행, 열 아무방향이나 다 합칠 수 있음. 합쳐서 없는 column이나 row값은 알아서 nan으로 들어감
- pd.concat([df1, df2], axis=1) : 이렇게 넣으면 옆으로 열추가되어 붙음
- pd.merge(df1, df2) : concat은 그냥 막 갔다붙인거라면, merge는 스며드는 친구. df2 중에서 df1의 사항에 맞게 없는 내용만 추가해서 옆으로 붙음.신상정보가 df1이고, 일부사람의 혈액형이 df2라면, df1에서 df2에 자료 '있는 사람만' 알아서 df1 옆으로 붙어짐.
열 (=시리즈) 기준 선택하기
- df['컬럼명'] : 해당컬럼만 선택하기
- df['컬럼1','컬럼2'] : 해당 컬럼들 선택하기
- df[df['OS'] == 'Android'] : 'OS' 컬럼 중에 'Android'인 행만 추가
- df[(df['OS'] == 'Android') & (df['MobileCompany'] == 'SKT' : OS열값이 Android이고 MobileCompany열값이 SKT인 행들만 선택하기
- df['HP'] + df['MP'] : HP 열 값과 MP 열 값을 더하기
- df['Avg'] = (df['HP'] + df['MP']) / 2 :Avg열을 만들고 HP 열 값과 MP 열 값의 평균값으로 채우기
- sales_data['date'] = sales_data['Time_stamp'].str[:7] : date라는 새로운 열을 time_stamp의 7번째 글짜까지만 끊어만듬
행 기준 선택하기 (=인덱싱하기)
- iloc : integer location : 숫자로 인자줘야함. 컴터기준
- df.iloc[행인덱스숫자] : 인덱스 11인 행 값
- df.iloc[11, :3] : 인덱스 11인 행 값 중 3번째 열까지 불러오기
- loc : location : 문자로 인자줘야함. 사람기준
- df.loc[11,['Customer_Id','Name','Nickname'] : 인덱스 이름이 11인 값 중 열 이름 'Customer_Id','Name','Nickname'에 대한 값
https://azanewta.tistory.com/34
iloc, loc를 사용한 행/열 선택법 from Pandas df
Pandas DataFrame에서 특정 행/열을 선택하는 방법은 여러가지가 있습니다. 단연코 Pandas를 사용하면서 이러한 선택의 기로에 많이 놓이게 됩니다. 어떤 방법을 써야될지 혼동이 오는 경우가 참 많죠.
azanewta.tistory.com
4.3 데이터프레임 고급 인덱싱 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
Groupby

정렬하기
- df['Avg'].idxmax(axis=0) :Avg열값 중 가장 큰 값의 인덱스 찾기
- df.sort_values(by=['Avg'], ascending=False) : Avg열값을 내림차순으로 정렬하기
- df.reset_index(drop=True) : df의 인덱스 정렬하기 (보통 sort를 하면 index넘버가 뒤죽박죽 되므로, 이를 다시 정렬)
상관관계
- df.corr()
- df['콜롬이름1'].corr(df['콜롬이름2'])) : 1과 2의 상관관계를 보여줌.
기타
- count(): NA를 제외한 수를 반환합니다.
- df['콜롬이름'].value_counts() : 범주형 데이터로 이루어진 컬럼에 대해 각 범주별로 값이 몇개인지 세어줌.
- df['콜롬이름'].value_counts().sum() : 몇개인지 세어준 것들의 합.
- min(), max(): 최소, 최댓값을 계산합니다.
- sum(): 합을 계산합니다.
- df['콜롬이름'].sum() : 원하는 컬럼의 합
- mean(): 평균을 계산합니다.
- median(): 중앙값을 계산합니다.
- var(): 분산을 계산합니다.
- std(): 표준편차를 계산합니다.
- argmin(), argmax(): 최소, 최댓값을 가지고 있는 값을 반환합니다.
- idxmin(), idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환합니다.
- cumsum(): 누적 합을 계산합니다.
- pct_change(): 퍼센트 변화율을 계산합니다.
df['datetime'].astype('datetime64[ns]')
df['datetime'].dt.year
df['datetime'].dt.month
df['datetime'].dt.day
df['datetime'].dt.hour
df['datetime'].dt.minute
df['datetime'].dt.second
Numpy 기본 명령어¶
다차원 배열인 ndarray를 사용하며, pandas를 이용한 고급 벡터계산 및 배열이 가능하다. list를 이용해 adarray에 접근 가능하다.
- df.sample(n=20) : 20개 무작위로 샘플링
- df.sample(frac=0.1) : 데이터프레임 중 10%를 샘플링
- np.corrcoef(df['성별'], df['키']) ; df안에 성별과 키 간의 상관계수 도출
https://nicedeveloper.tistory.com/40
기본수학, numpy
기본 수학 import numpy as np import statistics as st a = [9, 3, 5, 2, 7, 2, 6, 6, 7, 7, 8, 8, 10] 합계 : fsum(a) 평균 : np.mean(a) / st.mean(a) / np.average(a) ; weight 줄 수 있는 가중평균 중앙값: np.median(a) / st.median(a) n이 홀수
nicedeveloper.tistory.com
'Study (Data Science) > Python' 카테고리의 다른 글
| 프로그래머스) 배열 원소의 길이, 짝수 홀수 개수 (0) | 2022.12.02 |
|---|---|
| 막강한 클래스(Class) 2 (0) | 2022.12.02 |
| 기본수학, numpy (3) | 2022.12.01 |
| 게임 캐릭터 클래스 만들기 (0) | 2022.11.30 |
| 막강한 클래스 (Class) (0) | 2022.11.30 |



댓글