기본 수학
import numpy as np
import statistics as st
a = [9, 3, 5, 2, 7, 2, 6, 6, 7, 7, 8, 8, 10]
- 합계 : fsum(a)
- 평균 : np.mean(a) / st.mean(a) / np.average(a) ; weight 줄 수 있는 가중평균
- 중앙값: np.median(a) / st.median(a)
- n이 홀수 : n/2을 반올림한 순서의 값
- n이 짝수 : n/2번째 값과 ((n/2) + 1) 번째 값
- 배열이 짝수일 때, 낮은 중앙값 : median_low , 높은 중앙값 : median_high
- 최빈값 : np.bincount(a).argmax() / st.mode(a)
- 가장 빈도수가 많은 값. 가장 많이 나오는 값 : 7
- np.bincount(a) : 0부터 리스트상 최대값 숫자까지 각 숫자의 빈도를 list로 보여줌
- np.argmax(a) : 최대값의 'index number'를 반환
- 편차 (deviation) : 변량 - 평균
- 분산(variance) : np.var(a, ddof=1) / st.variance(a)
- 각 편차의 제곱의 합
- 편차를 다 양수로 만들기 위해 제곱하여 합함. 하지만 제곱때문에 실제값과 너무 차이가남.
- 분산이 크면, 분포가 크게 되어있다는 뜻
- 표준편차 (Standard Deviation) : np.std(a) / st.stdev(a)
- 분산에 루트씌운것. 편차의 제곱의 합에 루트.
- 실제값에서 떨어져있는 분산에 다시 루트를 씌움.
- = 오차범위 (절대편차(편차절대값의 평균)도 오차범위의 뜻이지만 보통 표준편차를 사용)
- 표준편차가 크면, 분포가 넓다는 뜻
import numpy as np
import statistics as st
a = [9, 3, 5, 2, 7, 2, 6, 6, 7, 7, 8, 8, 10]
a.sort()
print(a)
# 중앙값
# st.median(a) # 7
# np.median(a) # 7.0
# 평균
# st.mean(a) # 6.153846153846154
# np.mean(a)
# np.average(a)
# 최빈값 (가장 많이 나오는 값)
# st.mode(a) #7
# np.bincount(a).argmax() #7
# np.bincount(a) #0부터 10까지 각 숫자의 빈도를 list로 보여줌
# np.argmax(a) # 최대값의 '인덱스'를 반환.
# 분산
# np.var(a) # 5.9763313609467446
# np.var(a,ddof=1) # 6.4743589743589745
# st.variance(a) # 6.4743589743589745
# 표준편차
# np.std(a) # 2.4446536280108773
# st.stdev(a) # 2.5444761689508852list와 array의 차이점
- list : import가 필요없다. type 상관없이 append가 가능하다.
- array: import 필요하다. type은 int만 가능하다. append 대신 insert 쓰고, 들어갈 index 를 지정해준다.
NumPy
- np.array([1,2,3,4]) = np.arange(1,5)
- array안에는 같은타입만 가능. np.array([1,2,3,'4']) 하는 순간, 모든 숫자가 ' ' str로 형식이 바뀜
- ndarray 아니고, array는 r 두개, arange는 r 한개.
- .reshape(2,5), ndim : 차원을 바꿔주고, 몇차원인지 알려줌
- .dtype : type 알려줌
- 특수행렬
- 단위행령 : np.eye(3) ; (3,3) 출력하는데, (0,0),(1,1),(2,2)만 1이고 나머지는 0
- 0 행렬 : np.zeros([3,3]) : (3,3), 모든 요소가 다 0
- 1 행렬 : np.ones([3,3]) : (3,3), 모든 요소가 다 1
A = np.arange(10)
print(A) # [0 1 2 3 4 5 6 7 8 9]
B = A.reshape(2,5)
print(B) # [[0 1 2 3 4];[5 6 7 8 9]]
B.ndim # 2
A.dtype # dtype('int64')
print(A.dtype) # int64
5. Broadcasting : 일정 조건을 부합하는 다른 형태의 배열끼리 연산을 수행하는 것
- A = np.arange(9).reshape(3,3)일 때, 다른 행렬이나 정수의 사칙연산이 바로 가능
- python의 list가 하지 못하는 것이 가능하게됨.
6. Slicing
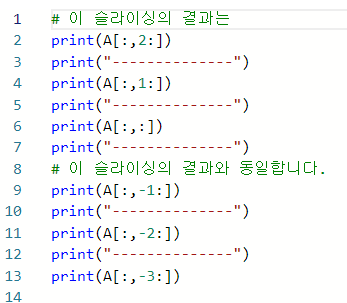
- 주의할 점은, 인덱스만 뽑은 것과 슬라이싱 했을 때의 dimension이 달라진다는 점이다.
- A = np.arange(9).reshape(3,3) 에서,
- 인덱싱 A[: , -1] ----> ([2, 5, 8]) : (1, 3)
- 슬라이싱 A[: , 2:] ----->([2],[5],[8]) : (3, 1) : 원본의 dimension을 유지시켜줌.
7. Random (난수)
- np.random.random() #0에서 1사이의 실수 1개 생성
- np.random.randint(0, 10) #0-9사이의 정수 1개
- np.random.choice([0,1,2,3]) # 리스트 주어진 값 중 랜덤 1개
- np.random.permutation(10) # 0-9까지 무작위로 배열 섞음
- np.random.normal(loc=0, scale=1, size=5) # 평균loc, 표준편차scale, 추출개수size --> 정규분포를 따르는 표본추출
- np.random.uniform(low=-1, high=1, size=5) # 최소, 최대, 추출갯수 --> 균등분포를 따름
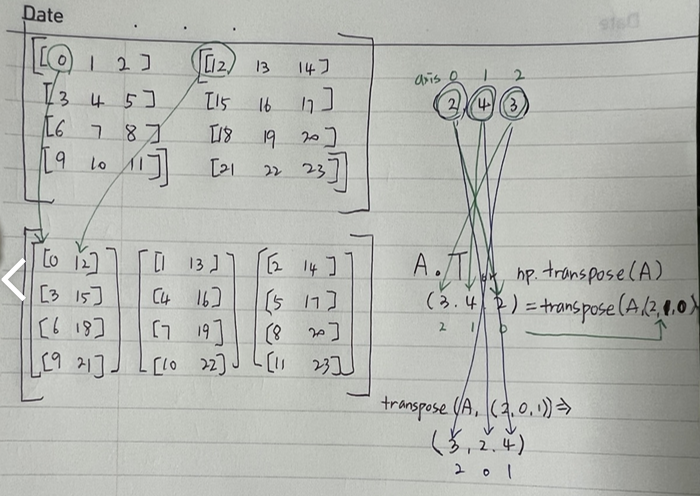
8. 전치행렬
.T = np.transpose()
A = (2,4,3) 의 행렬이라면,
A = (axis0, 1,2) 의 순서로 두고
np.transpose(A,(2,0,1))로 바꾸면 축번호순으로 다시 reshape하여서
A = (3,2,4) 가 된다.
이해가 안가서 한참을 했네..
9. 여러가지 데이터들의 shape
- 소리 : 1차원 array로 표현한다. CD음원파일의 경우, 44.1kHz의 샘플링 레이트로 -32767 ~ 32768의 정수 값을 갖는다.
- 픽셀
- 픽셀자체는 2차원 사각형인데, RGB값을 넣으려고 3개의 요소를 가진 튜플형태로 나타낸다. (3차원 아님)
- 흰색(W) : (255,255,255)
- 검정색(B) : (0, 0, 0)
- 빨간색(R) : (255, 0, 0)
- 파란색(B) : (0, 0, 255)
- 녹색(G) : (0, 128, 0)
- 노란색(Y) : (255, 255, 0)
- 보라색(P) : (128, 0, 128)
- 회색(Gray) : (128, 128, 128)
- 픽셀의 모음이 이미지.
- 흑백이미지 : (h* w)
- 이미지 사이즈의 세로X 가로 형태의 행렬(2차원 ndarray)로 나타내고, 각 원소는 픽셀별로 명도(grayscale)를 0~255 의 숫자로 환산하여 표시한다. 0은 검정, 255는 흰색이다.
- 컬러이미지 : (h* w * 3)
- 이미지 사이즈의 세로 X 가로x3 형태의 3차원 행렬이다. 3은 Red, Green, Blue계열의 3 색을 의미한다.
- w * h 형태의 2차원 형태가 RGB 총 3차원으로 겹쳐있는 모양. (3 * w * h) 라고 쓰지 않고, 3을 가장 뒤에 쓴다.
- 자연어 : embadding 후 1차원 array
- 1단계 : 토큰화 : 단어별로 나누어 인덱싱하기
- 2단계 : 임베딩 : batch size, sequence length, embedding size를 줘서 차원을 늘려 쌓은 후
- 3단계 : 한번에 합쳐서 1차원 adarray가 됨.





(((((헷갈리는 부분)))))
이미지 크기는 보통 (w, h)이다.
하지만 이를 np.array로 표현하면, (h, w, channel)이 된다.
자유의 여신상 그림을 예로 들면,
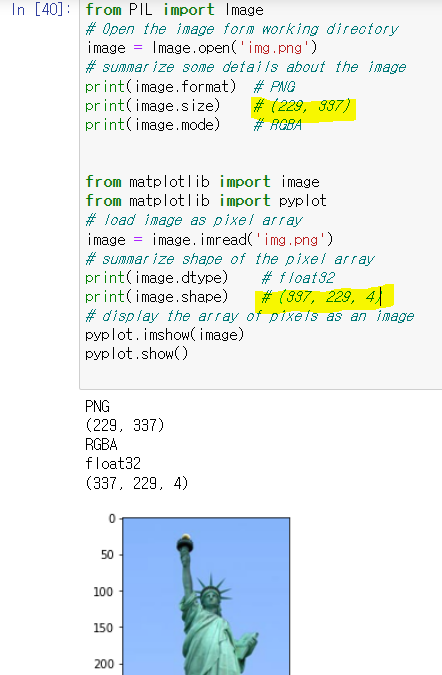
참고https://doyou-study.tistory.com/82
http://jalammar.github.io/visual-numpy/
A Visual Intro to NumPy and Data Representation
Discussions: Hacker News (366 points, 21 comments), Reddit r/MachineLearning (256 points, 18 comments) Translations: Chinese 1, Chinese 2, Japanese, Korean The NumPy package is the workhorse of data analysis, machine learning, and scientific computing in t
jalammar.github.io
728x90
'Study (Data Science) > Python' 카테고리의 다른 글
| 막강한 클래스(Class) 2 (0) | 2022.12.02 |
|---|---|
| Pandas, NumPy (0) | 2022.12.01 |
| 게임 캐릭터 클래스 만들기 (0) | 2022.11.30 |
| 막강한 클래스 (Class) (0) | 2022.11.30 |
| Unit 31. 재귀호출 (recursive call) (0) | 2022.11.29 |



댓글