GAN의 목적
1. Pg -> Pdata (만들어낸 이미지의 분포가 실제 이미지의 분포로 수렴하면 성공)
2. D(G(z)) -> 1/2 (Generator가 만들어낸 결과(G(z))를 Discriminator가 판별했을 때, 1이 진짜, 0이 가까이지만 잘 모르겠어서 1/2로 판별해내면 성공. 첨에는 0으로 잘 가려내겠지만 나중에는 1인가? 하다가 결국 그 평균인 1/2에 수렴해야함)

- D(x) : x는 진짜에서 뽑아온 분포니, D가 판별했을 때 진짜이도록, 즉 1이 되도록
- D(G(z)) : G(z) output 자체가 가짜니
- D입장에서는 ; D가 판별했을 때 가짜이도록, 즉 0이 되도록
- G입장에서는 ; D가 판별했을 때 진짜이도록, 즉 1이 되도록
- 결국, log 1 + log 0.5 가 될 것임.
log 0 = undefined
log 0.5 = 약 -0.301
log 1 = 0
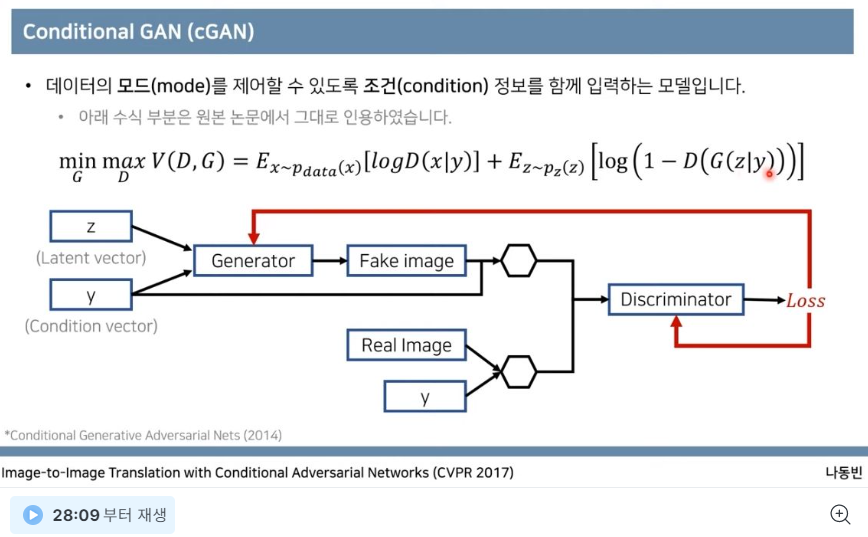
cGAN의 목적 (Conditional GAN)
condition 을 concated 하여 input으로 함께 제공하고, (like guideline) 더 정확한 이미지를 생성하도록 함

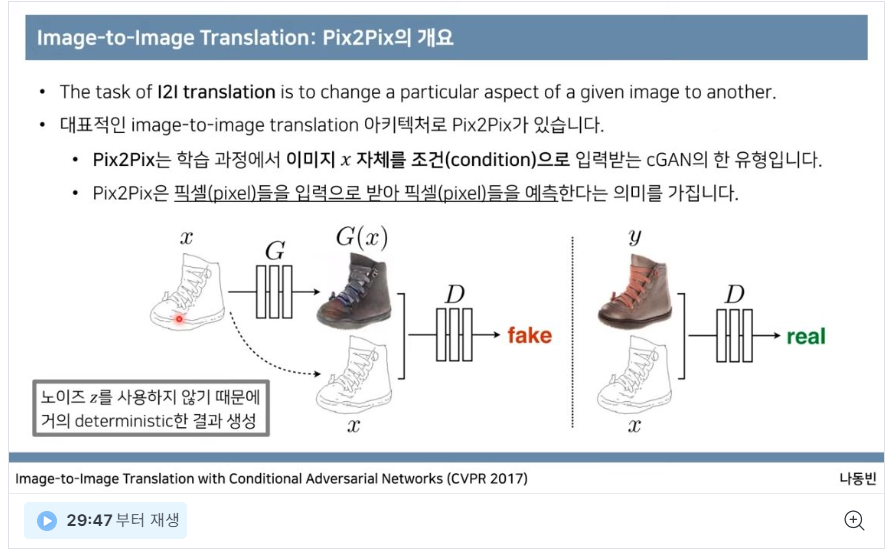
pix2pix의 목적
손스케치만 되어있는 input picture로 label인 REAL pic과 유사한 FAKE pic을 generator가 생성해내는 것.
유의점 : condition을 나타내는 문자가 y에서 x로 변경된 것 주의.

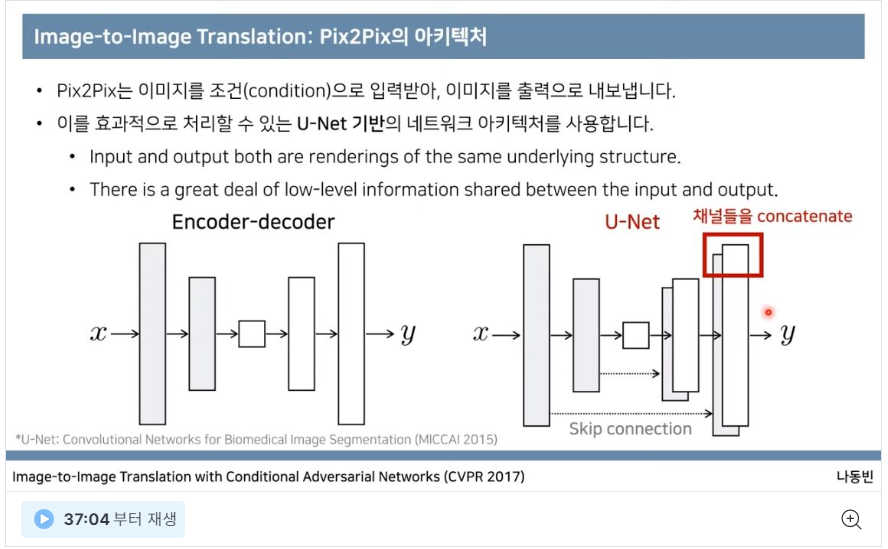
구조 : U-NET + L1 + cGAN + patchGAN
- U-NET을 쓴 이유
- Encoder-Decoder 방식과 달리 그 구조가 >< 이러하여 사진에서 사진이라는 데이터 형질을 잘 반영할 수 있게 해주고, > 부분의 사전정보를 < 쪽으로 잔차연결처럼 정보를 제공하여 좀 더 쉽고 정확한 정보로 학습할 수 있음.
- L1을 쓴 이유
- L1 : MAE (Absolute) / L2 : MSE (Squared)
- L1은 실제-가짜간의 편차의 절대값이라 outlier에 L2보다 less sensitive, blurry함
- L2보다 기울기 손실의 가능성이 적기 때문에 보다 안정적인 학습이 가능함
- 실제 이미지와 정확하게 일치하는 복제본을 생성하도록 강제하지 않아 다양한 출력이미지가 가능
- GAN이 아닌 cGAN을 쓴 이유
- condition인 손으로 그린 그림을 함께 input으로 전달하면서 훨씬 real image에 가까운 이미지가 생성가능
- GAN은 노이즈를 input으로 받아 sharp한 형태의 output을 위해 많이 학습 필요
- patchGAN이란
- Discriminator 모델이 사용하는 부분적인 GAN
- patch를 단위로 진짜 (1) 와 가짜(0)를 구분하게 됨
- 좁은단위가 기준이 되어 파라미터 양이 적고, 시간단축 가능
- 더 디테일한 피드백으로 real image에 가까운 학습을 도움
- 이미지의 위치적 특성이 많이 들어갈 수 있음
- Generator가 더 다양한 이미지를 만들도록 권장하여 diversity good.
- input 이미지가 커도 별 부담이 없음

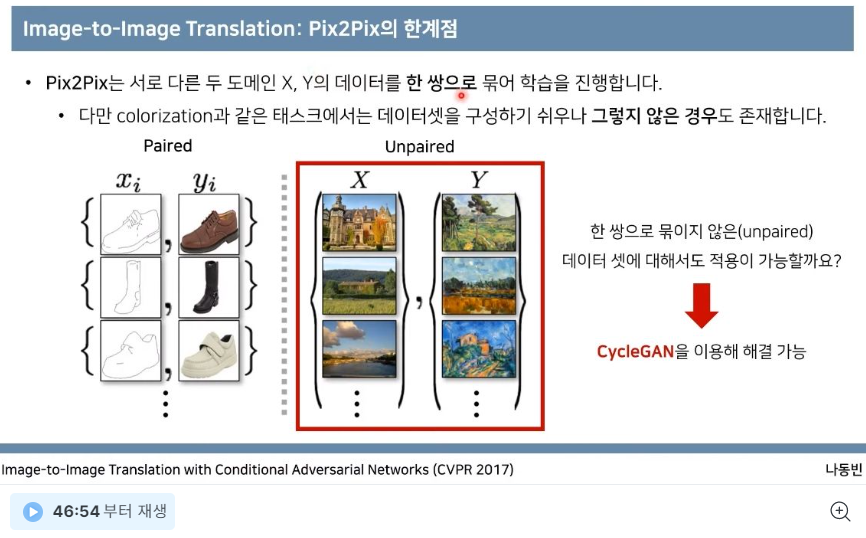
참고자료들



'Study (Data Science) > CV' 카테고리의 다른 글
| Diffusion 2 (Stable diffusion) (0) | 2023.04.12 |
|---|---|
| AE, DAE, VAE (0) | 2023.03.31 |
| OCR (광학문자인식)과 딥러닝 (0) | 2023.01.31 |
| 생성 모델들 / GAN (0) | 2023.01.17 |
| Convolution Layer 심화학습 (0) | 2022.12.29 |




댓글