벡터화
분산표현이 대중화되기 전에 쓰이던 방법
단어의 의미! 를 부여하기 위한 인간의 노력들.
크게 빈도 / 분포 를 이용한 두가지 방법으로 나뉨
단어 빈도를 이용한 벡터화
1. BoW (Bag of Words)
문서 내 단어들을 다 쪼개서 >> 하나의 가방에 넣고 순서 무시하고 흔들어버림 >> 단어별 빈도수에 따라 정렬 >> 단어 분포를 보고 문서의 특성을 파악
- Keras로는 tokenizer.word_counts를 딕셔너리로 만들면 BoW.
- sklearn로는 CountVectorizer.fit_transform(sentence).toarray() 로 BoW 만듬.
- Bow에는 단어별 빈도수까지 들어있기 때문에 단순 단어 색인인 fit_on_texts로 만든 word_index와는 다름.
- 한계 : 어순에 따라 달라지는 의미를 캐치할 수 없음. I ate lunch / Lunch ate I.
2. TDM (Term-Document Matrix)
Row : Words / Column : Documents
or
DTM (Document_Term Matrix)
Row : Documents / Column : Words
Bag of Words를 하나의 행렬로 구현한 것.
각 문서에 등장한 단어의 빈도수를 하나의 행렬로 통합.
코사인 유사도를 계산할 수 있다는 장점이 있음.
- 희소벡터 (spars vector) : 0인 친구들
- 단어장 (vocabulary) : 중복단어를 제외한 단어들의 집합(set)
단점
- 너무 0 이 많아서 sparse 하고, 단어수가 늘어날 수록 깊이(차원)이 늘어남 (차원의 저주)
- frequency에 집중하다 보니 관사같이 어쩔 수 없이 많이 쓰이는 단어가 다른 두 문서에 공통적으로 많으면 이 둘이 유사하다고 착각할 수 있음.
그래서 중요한 단어와 중요하지 않은 단어에
가중치를 따로 선별해서 주는 방법이 필요하게 됨.
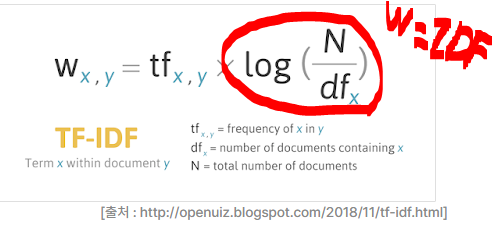
3. TF-IDF (Term Frequency-Inverse Document Frequency : 단어의 빈도수- 문서 빈도의 역수)
각 단어의 중요도를 판단하여 가중치를 주는 방법
모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며 (like. 관사같은 stopwords),
특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
TF-IDF가 DTM보다 성능이 좋지는 않음
그래서 TF = DTM이니 단어 빈도에 대한 DTM을 구해두고
거기에 IDF만 다시 구해서 곱해주면 됨. (IDF = Weight)
여전히 단어장(V)의 크기는 같고, 희소벡터도 그대로라서 겉보기엔 DTM과 똑같음
- log를 취해주는 이유
- IDF 값이 작아져도 너무 빨리 0으로 수렴하지 않고, 보다 자연스러운 가중치 값을 얻을 수 있음.
- 로그를 취하는 것은 IDF 값의 척도를 축소시키기 때문에, 희귀한 단어에 대한 가중치를 더 부각시켜주고, 반대로 자주 나타나는 단어의 가중치를 줄임. 이로써, 문서에서 중요한 키워드를 식별하는 데 도움됨.
- TF-IDF가 BoW보다 나은 이유
- 단어의 빈도수 외에 문서 집합 전체에서의 중요성을 고려
- 벡터 표현의 차원을 줄여 효율적인 분석 가능
- 불용어(Stopwords) 처리의 필요성 감소 (단어의 중요성을 고려하므로 관사를 굳이 제외할 필요도 없음)
예제) 문서가 5개고, 2개에서만 like 단어가 등장, 2번문서에서 200번, 3번문서에서 300번 등장했다.
2,3번 문서에서의 like의 TF-IDF는 얼마인가?
DF (문서의 빈도) : 2 (2개문서에서 등장했으므로)
N (전체 문서의 수) : 5IDF : log 5/2 (약 0.92)2번문서 like의 TF-IDF : 200 * 0.92 = 약 183
3번문서 like의 TF-IDF : 300 * 0.92 = 약 274
>> TF-IDF의 목적이 특정 문서에서만 자주 등장하는 단어는 중요도는 높다고 판단한다는 것이었으므로,
1번문서에서 한번도 등장하지 않았던 like가 3번문서에 300번이나 등장하니 중요하다고 할 수 있음.
4. TF-IDF의 코사인 유사도 구하는 방법
참조 : ( https://www.youtube.com/watch?v=Rd3OnBPDRbM&t=3s )










DTM이나 TF-IDF 외에 원-핫 인코딩도 있음
원-핫 인코딩 (one-hot encoding)
먼저 모든 단어들의 Vocabulary를 만든 후에 하나씩 1을 부여하는 방법
모든 단어의 관계를 독립적으로 정의하는 방법임
단어 '빈도' 베이스에서 더욱 발전되어 '분포'로 단어의 의미를 고려하기 시작
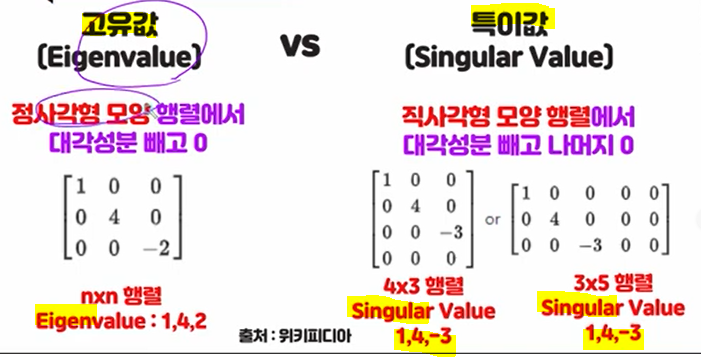
특잇값 분해 (Singular Value Decomposition)
차원 축소의 방법 중 하나.
데이터(=행렬,matrix)를 Singular Value를 가진 행렬로 분해하는 것.
SVD = 행렬 A를 USV 행렬로 분해
- U,V 행렬은 직교행렬로 vertical, horizonal한 모양의 행렬이며, A행렬을 회전시키는 역할을 하고,
- S는 sparse한 행렬을 특잇값만 뽑으므로써 차원축소를 하기 때문에, A행렬을 늘리고 줄이는 역할을 한다.
- S행렬의 특잇값이 대각선으로 분포되어 있으니 화면을 대각선으로 늘리고 줄이는 개념으로 이해하면 된다.
- 대각선 방향으로 값이 많으면 늘어나는것, 적으면 줄어드는것.
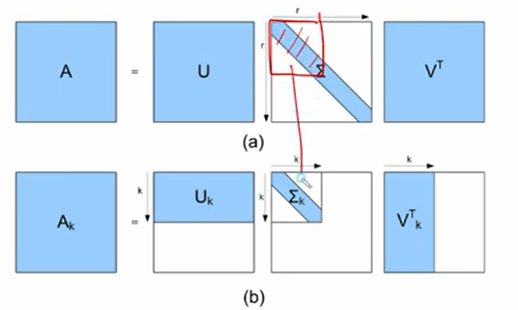
- Full SVD : A = U행렬 x S행렬(특이값행렬) x V행렬
- Trucated SVD : Ak = Uk X Sk X Vk (k는 S에서의 영역임. 밑에 사진 참고)
- 위 : full / 아래 : Trucated
Singular Value :
직교행렬 :

4. LSA (Latent Semantic Analysis :잠재 의미 분석)
DTM 만들고 -> t개의 차원으로 Truncated SVD 해서 -> 정보 유지하며 차원축소
축소된 DTM이 있으니 잠재의미분석. 전체 코퍼스 속에서 문서속 단어들의 관계를 찾아내거나,
단어-단어, 단어-문서, 문서-문서간 의미적 유사성 점수를 알 수 있음.
LSA는 DTM이나 TF-IDF 행렬에 Truncated SVD를 수행하며
분해된 행렬 3개는 각각
- Uk : 문서들과 관련된 의미들을 표현한 행렬
- (문서의 수(m), k)
- 의 각 행 : 각 문서를 표현하는 문서 벡터
- Sk: 단어들과 관련된 의미를 표현한 행렬
- Vk: 각 의미의 중요도를 표현한 행렬
- (k, 단어의 수(n))
- Vk의 각 열 : 각 단어를 나타내는 차원의 단어 벡터
- k열 : 전체 코퍼스로부터 얻어낸 개의 주요 주제(topic)
- 행렬 Vk가 k × (단어의 수) 의 크기가 되고,
- 각 행 (원래는 행이 문서, 문장, 열이 단어)을 전체 코퍼스의 k개의 주제(topic)로 가정하고,
- 내가 준 k의 갯수만큼 각 행의 단어 중 가장 value가 높은것부터 추출하면
- 이게바로 토픽추출.
- DTM, TF-IDF 가 단어 임베딩이 되지 않고, LSA는 되는 이유.
- DTM과 TF-IDF는 단어들의 고차원 벡터 표현을 제공하지만, 이들은 단어의 의미를 캡처하는 것이 아니라, 단어의 출현 빈도수만을 반영합니다. 따라서 이러한 표현들은 단어 간의 유사도를 측정하는 데는 유용하지만, 단어들의 의미나 문맥을 완전히 이해할 수는 없습니다.
- 반면에 LSA는 차원 축소를 통해 단어들 간의 의미적 유사도를 캡처하려고 시도합니다. LSA는 단어들이 사용된 문맥의 유사성에 기반하여 단어들 간의 상호작용을 모델링하고, 이를 통해 단어들의 의미를 파악합니다. 이러한 LSA의 특성은 단어 임베딩으로 활용될 수 있습니다. 예를 들어, LSA에서 차원 축소된 결과를 사용하여 각 단어를 고정된 길이의 벡터로 표현할 수 있으며, 이러한 벡터는 단어 간의 의미적 유사성을 반영합니다. 이러한 LSA 기반의 단어 임베딩은 다양한 자연어 처리 태스크에서 사용될 수 있습니다.
- 이렇게 계산된 문서-단어의 잠재의미 벡터들은 벡터간의 코사인 유사도를 계산하여 문서와 단어 사이의 의미적 유사성을 측정할 수 있습니다. 보통은 여러 문서 중에서 하나의 문서를 샘플링하여 해당 문서와 각 단어 벡터의 코사인 유사도를 계산하고, 이를 내림차순으로 정렬하여 가장 유사한 단어를 추출합니다. 이렇게 추출된 단어들은 해당 문서와 유사한 문맥에서 자주 등장하는 단어들이기 때문에, 문서의 의미를 잘 반영하는 단어들입니다.
토픽 모델링(Topic Modeling)
- 토픽 모델링은 문서 집합에서 주제를 찾아내기 위한 기술
- 토픽 모델링은 '특정 주제에 관한 문서에서는 특정 단어가 자주 등장할 것이다'라는 직관을 기반
- 예를 들어, 주제가 '개'인 문서에서는 개의 품종, 개의 특성을 나타내는 단어가 다른 문서에 비해 많이 등장
- 주로 사용되는 토픽 모델링 방법은 잠재 의미 분석과 잠재 디리클레 할당 기법이 있음
5. LDA (Latent Dirichlet Allocation : 잠재 디리클레 할당)
LSA와 함께 토픽 모델링의 또 다른 대표적인 알고리즘.
모든 단어는 하나의 토픽에 속하고, 임의의 단어가 있을 때 이것이 어떤 토픽이 될 껀지 찾아내는 알고리즘
'나는 이 문서를 작성하기 위해서 이런 주제들을 넣을거고, 이런 주제들을 위해서는 이런 단어들을 넣을 거야.'
주제와 문서 / 주제와 단어간의 확률로 토픽 추출.

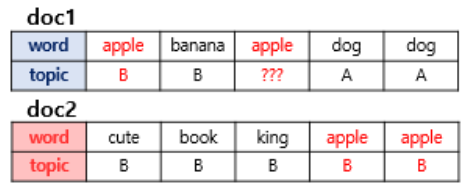
???의 부분, 즉 doc1의 apple 단어의 토픽을 찾아내려면,

총 docs 중 토픽이 몇개인지 보고, 그 확률을 구함
여기선 A, B이니 각각 50% 의 확률

총 docs의 해당단어들이 각각의 토픽에 속한 확률을 구함
여기선 apple이 거의 B에 해당되었으므로,
해당 ??? 도 B로 할당될 확률이 높음.
- LDA는 비지도 학습이라는 점을 인지한 상태에서 LDA 결과 해석시 주의해야 할 점
- 토픽이 명확하지 않을 수 있음: LDA는 문서 내에서 단어들의 패턴을 통해 토픽을 추출하기 때문에, 토픽들이 어떤 의미를 갖는지 명확하지 않을 수 있습니다.
- 토픽 수에 따른 결과의 변화: 토픽 수를 조정하면 LDA 모델에서 생성된 토픽들이 달라질 수 있습니다. 따라서, 토픽 수를 조정하는 과정에서 어느 정도 주관적인 판단이 필요합니다.
- 토픽들의 이름 부여: LDA에서 생성된 토픽들은 숫자나 단어의 집합으로 나타나기 때문에, 해석하기 어려울 수 있습니다. 따라서, 토픽들에 의미 있는 이름을 부여하는 작업이 필요합니다.
- 문서와 토픽 간의 관계 해석: LDA에서는 문서를 토픽의 분포로 나타내기 때문에, 각 문서가 어떤 토픽과 어떤 정도의 관련이 있는지 해석하는 것이 중요합니다. 이를 위해서는 토픽 분포와 문서 분포를 시각화하거나 분석하는 등의 작업이 필요합니다.
- 전처리 과정의 중요성: LDA 결과에 영향을 미치는 요소 중 하나는 전처리 과정입니다. 따라서, 전처리 과정에서 어떤 단어를 제거하고 어떤 단어를 포함할지를 결정하는 것이 중요합니다
- LSA와 LDA의 차이점
- LDA(Latent Dirichlet Allocation)와 LSA(Latent Semantic Analysis) 모두 토픽 모델링을 수행하기 위한 방법론 중 하나입니다. 하지만 LDA와 LSA는 각각 다른 방식으로 토픽 모델링을 수행합니다.
- LSA는 DTM(Document-Term Matrix)을 생성하고, DTM을 SVD(Singular Value Decomposition)로 분해하여 밀집 행렬로 만듭니다. 이 밀집 행렬에서 단어 간 유사도와 문서 간 유사도를 계산하여 토픽을 도출합니다. 즉, LSA는 단어의 잠재적 의미를 추출하기 위해 DTM을 밀집 행렬로 변환하고, 이를 기반으로 토픽을 도출합니다.
- LDA는 문서 집합을 확률 분포로 모델링하여, 주제에 속하는 단어의 확률 분포와 문서가 특정 주제를 가질 확률 분포를 계산합니다. 이렇게 계산된 확률 분포를 기반으로 문서의 주제 분포와 주제의 단어 분포를 추출하여 토픽을 도출합니다. 즉, LDA는 문서의 분포와 단어의 분포를 계산하여, 이를 기반으로 토픽을 도출합니다.
- LDA는 확률 분포를 이용해 토픽을 모델링하므로, 결과 해석이 어려울 수 있습니다. 또한 LDA는 알고리즘 자체가 상대적으로 복잡하기 때문에, LSA보다 수행 시간이 오래 걸릴 수 있습니다. 하지만 LDA는 DTM이나 TF-IDF와 같이 수치화된 데이터보다는 원시 텍스트 데이터에 적용하기 적합하며, 토픽 간의 상호 작용을 고려하여 토픽 간의 연관성을 파악하는 데 유용합니다.
'Study (Data Science) > NLP' 카테고리의 다른 글
| 토큰화 / 인덱싱 / 벡터화 / 임베딩 (0) | 2023.02.22 |
|---|---|
| 벡터화 발전과정 2 - soynlp (비지도학습 한국어 형태소 분석기) (0) | 2023.02.20 |
| Keras Tokenizer 와 SentencePiece 비교 이해 (0) | 2023.02.15 |
| 전처리, 분산표현, 임베딩, 토큰화 (0) | 2023.02.14 |
| Chatbot (0) | 2023.01.27 |



댓글