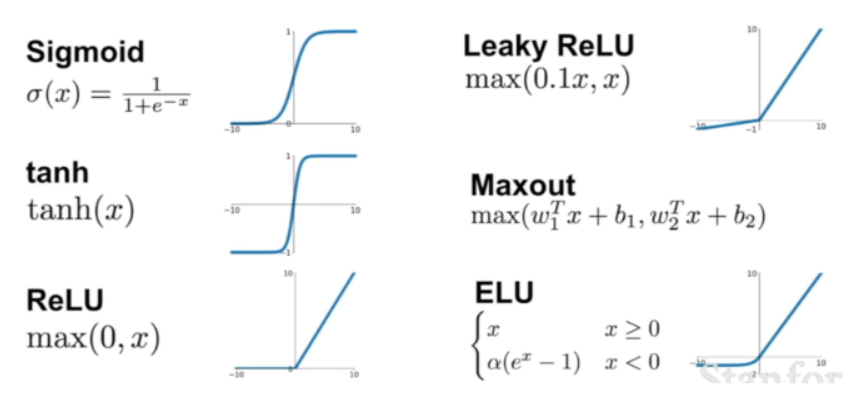

- vanishing gradient 현상이 발생한다. (0과 1에 결과값이 포화 saturate 된다. 포화된다는 말 자체가 kill the gradient. 기울기가 죽어버리면 에포크를 많이 돌려도 더이상 학습되지 않는다. )
- exp 함수 사용 시 비용이 크다.
- 요즘은 ReLU를 더 많이 사용한다.

- Hyperbolic Tangent : 쌍곡선 함수 중 하나. (쌍곡선함수 hyperbolic tuction : 일반 삼각함수와 유사한 성질을 갖는 함수지만 삼각함수와 달리 주기함수는 아니다.
- tanh 함수는 함수의 중심값을 0으로 옮겨 sigmoid의 최적화 과정이 느려지는 문제를 해결.
- vanishing gradient 문제 존재. (값이 1, -1에 포화됨)


- sigmoid, tanh 함수에 비해 학습이 빠름. 에포크당 훈련비율이 7배정도 빨라진다고 AlexNet 논문에 기술됨.
- 연산 비용이 크지 않고, 구현이 매우 간단.
- x = 0 일 때만 제외하고 모든 구간에서 미분이 가능. 음수면 0, 양수면 1로 값을 정제함.
- 하지만 x = 0이면, 즉 그래디언트를 구하는 과정 중 0이 주어지면 무작위하게 0 혹은 1을 출력하게 됨.
- 이전 훈련 스텝 가중치가 업데이트 되면서 한번 0이하로 떨어지만, 그 이후의 그래디언트도 모두 0으로밖에 나오지 않는 Dying ReLU 문제가 있음. 이렇게 되면 기울기가 0이 되면서 학습이 되지 않음. 하지만 이는 학습률을 크게 잡을 때 발생하는 문제로 lr을 줄여주면 해결할 수 있음.
ReLU의 단점을 해결하고자 했던 다른 함수들
- PReLU(parametric ReLU) : Leaky ReLU와 유사하지만 새로운 파라미터를 추가하여 0 미만일때도 기울기가 훈련되기 하였음.

- ELU(Exponential Linear Unit) : 0일때에도 계산되게 하면서 (알파를 추가함) Dying ReLU를 해결하였음. 하지만 exponential연산이 들어가면서 계산비용이 높아짐


딥러닝에서 사용하는 활성화함수
An Ed edition
reniew.github.io
https://pozalabs.github.io/Activation_Function/
Activation Function
Activation Function summary
pozalabs.github.io
06. 비선형 활성화 함수(Activation function)
비선형 활성화 함수(Activation function)는 입력을 받아 수학적 변환을 수행하고 출력을 생성하는 함수입니다. 앞서 배운 시그모이드 함수나 소프트맥스 함수는 대표적인…
wikidocs.net
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339
딥러닝 - 활성화 함수(Activation) 종류 및 비교
# 활성화 함수 딥러닝 네트워크에서 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달...
blog.naver.com
https://hyeonji-ryu.github.io/2020/05/02/DeeplearningJulia/Deeplearning-10/
10. ReLU vs. Sigmoid 성능 비교
해당 시리즈는 프로그래밍 언어 중 하나인 줄리아(Julia)로 딥러닝(Deep learning)을 구현하면서 원리를 설명합니다.
hyeonji-ryu.github.io
728x90
'Study (Data Science) > DL' 카테고리의 다른 글
| Regularization, Normalization (0) | 2023.01.11 |
|---|---|
| model.summary 에서의 param# 구하기 (0) | 2023.01.06 |
| 인공지능, 머신러닝 그리고 딥러닝 (4) | 2022.12.27 |
| TF-IDF (0) | 2022.12.19 |
| 시계열 개념 / ADF Test / 시계열 분해 /ARIMA (0) | 2022.12.18 |



댓글