
인공지능
사람이 직접 프로그래밍 하지 않고, 기계가 자체 규칙 시스템을 구축하는 과학
머신러닝
데이터를 통해 스스로 학습하는 방법론. 데이터를 분석, 패턴학습, 판단,예측을 수행함.
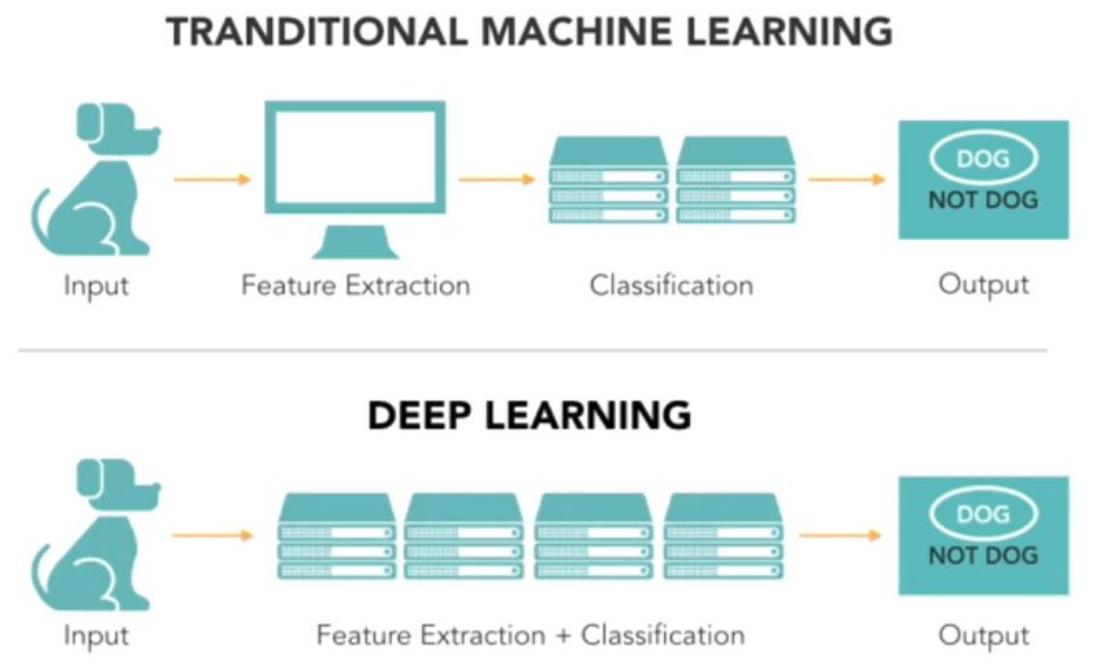
- 기존의 머신러닝은 데이터를 입력하기 위해 사람이 직접 피처(Feature)를 가공한다. 데이터의 여러가지 표현방식 중 주로 '표' 형태로 된 정형 데이터를 처리하도록 설계되었기 때문. 그래서 데이터 전처리나, 좋은 피쳐를 조합하여 만들거나 하는 피처 엔지니어링(Feature Engineering) 이 중요하다. 그만큼 머신러닝은 더 좋은 모델을 만들기 위해 '사람의 개입'이 많다.
딥러닝
머신러닝의 하위 집합이며, 그 과정의 모델 형태가 신경망인 방법론.
Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.
- 데이터의 내재적 표현 중에서 좋은 표현 (good representation)을 추출해내는 것.
- 내재적 표현 (internal representation) : 데이터가 담고 있는 정보의 총체, 혹은 함의를 나타내는 표현
- 내재적 표현 추출 : 데이터 안에 내재되어 있는, 추상적인 표현을 추출
- 피쳐 엔지니어링을 최소화하고, 사람의 개입을 최소한으로 줄여 학습된 함수를 사용하여 유용한 internal representations, 즉 내재적 표현을 뽑아내는, 즉 사람 개입 없이 데이터를 모델에 입력해서 바로 원하는 출력값을 얻어내는 End-to-End Learning을 추구
- 자연어처리나 이미지 와 같이 뚜렷한 형태가 없는(비정형) 데이터로부터 표현을 추출해 내는 것을 잘함.
- 퍼셉트론을 빌딩 블록으로 하여 쌓아올린, 심층 신경망을 러닝 모델로 사용하는 머신러닝 방법론
- 예시 : 만약 입력되는 이미지의 크기가 (224x224x3)이었다면 약 15만 개의 숫자로 데이터가 표현.. 이를 잘 학습된 딥러닝 네트워크에 먹이면 단 1,000개의 숫자만으로 그 이미지의 내재된 특성들을 모두 표현할 수 있게 됨 (사람 도움 없이 자기 혼자 특성 추출). 한 번 잘 학습시켜 두면, 그 뒤 몇십만장의 이미지도 잘 처리하게 됨.
- 강점
- ‘요인 표현 학습(feature representation learning)’ 능력을 가지고 있으며, 이는 원본 데이터로부터 최적의 성능을 발휘하는 데 사용될 수 있는 요인 표현 방법을 스스로 학습하고, 이를 기반으로 최적의 성능을 발휘하는 가중치를 더욱 효과적으로 찾는 능력을 말한다.
- 약점
- 굉장히 많은 데이터가 필요하며, 학습 연산량이 매우 높아 학습 시간이 오래 걸린다는 것이 약점이다.
딥러닝 탄생의 학문적 이데올로기 배경
1. 행동주의
- 인지과학 (인간의 지능을 자극과 반응의 관계로만 설명하던 행동주의 심리학에 반발하면서 등장한 학문)의 행동주의는 인간의 지능이 '자극 → 행동' 과정의 반복으로 만들어진다고 주장. 인간, 혹은 인간뿐만 아니라 모든 생명체의 지능은 반복되는 자극에 따라 형성.
- 무의식과 같이 관찰될 수 없는 것을 배제하였으며, 인간의 행동은 자극으로부터 직접적으로 만들어진다고 주장. '자극 → 행동'의 흐름에 따라, 인간의 지능 및 내면은 살아가면서 받는 자극으로 형성되는 후천적인 것이라고 주장.
- 학자 스키너(Skinner)는 비둘기에게 적절한 보상을 줌으로써 탁구를 학습시키는 것이 가능하다는 것을 실험으로 보여줌. 조작적 조건화(Operant Conditioning) ; 생명체가 외부에서 받는 자극으로 인해 학습되는 과정
- 스키너 상자 : 동물행동 연구장치. 박스에 쥐를 넣고 레버를 둔다. 레버를 눌러 먹이가 나오는 자극을 받을 때 쥐는 더 반복적으로 그 횟수를 많이 눌렀고, 먹이가 나오지 않았음을 알았을때는 그 빈도가 줄어들었다.
- 강화 (Reinforcement) : 먹이. 어떤 행동을 했을 때 상으로 제공하는 것. 자기에게 유리한 결과를 가져다 주는 행동. 컴퓨터의 강화학습 역시 실제로 특정 행위자를 학습시키기 위해 행위자가 하는 행동이 얼마나 좋았는지에 대한 척도인 '보상'을 부여하고, 행위자는 그 보상을 높이기 위해 자신의 행동을 교정하면서 학습해나감.
- 한계점
- 인간의 내면을 지나치게 단순화. 단순히 반복되는 자극에 따라 행동을 '강화'함으로써 학습되는 것이 아니라, 인간의 뇌 안에서 기억, 주의 등의 일련의 정보처리 과정을 거친 후 행동을 만들어낸다는 주장이 노암 촘스키(Noam Chomsky)에 의해 새롭게 제기됨. 이렇게 행동주의를 반대하며 제기된 학문이 바로 인지심리학.
2. 지각심리학 (Perceptual Psychology) / 인지심리학 (Cognitive Psychology)
- 인지주의는 '자극 → 행동'의 관계만 설명하던 행동주의에 대해 반발하며 '자극 → (정보처리) → 행동' 의 관점을 제시
- 인간의 행동이 단순히 자극으로부터 만들어진다는 주장으로 인간의 '의식'을 부정했던 행동주의와 달리, 인지주의는 인간이 자극을 받은 후 내면에서 정보를 처리하고 가공하는 의식이 존재함을 주장.
- 즉, 인지심리학은 인간의 마음을 일종의 정보 처리 체계로 보고 접근하고, 이에 따라 인간의 뇌가 정보를 처리하는 과정에 대해 관심을 가지며 '신경과학'이라는 새로운 분야를 만들어냄.
- 인지주의는 자극과 반응 사이에 있는 '정보처리' 과정에 관심. 생명체의 지능은 단순히 어떤 행동을 자극에 맞추어 '강화'하는 것을 넘어서서, 자극을 받아 반응을 하기까지 복잡한 알고리즘을 통해 정보를 처리하는 것이라고 생각.
- 한계점
- 하지만 그 정보처리 과정을 구체적으로 설명하지 못함.
3. 연결주의 (Connectionism)
- 인지심리학의 한계점이었던 정보처리 과정을 설명함.
- 자극으로부터 반응을 하기까지의 과정에서 뉴런과 같이 연결되어 있는 모형이 정보를 처리해 나간다고 설명.
- 이에 따라 연결주의의 지능체는 처음에는 '백지' 상태이며, 다수의 사례를 주고 '경험'함으로써 스스로 천천히 '학습'해 가며, 학습된 내용은 연결된 뉴런 자체에 저장되어 있으며, 외부에서 자극을 받음에 따라 그 연결 형태가 바뀌면서 학습된 내용이 바뀌어간다고 주장.
- 앞선 인지주의를 관통하는 문제의식은 '자극을 받아 반응을 하기까지, 생명체 내부에서 정보가 어떻게 표현되거나 처리되기에 "지능"이라는 현상이 나타나는가?'라고 할 수 있고, 이의 '정보를 표현하거나 처리하는 방법'에 대해 답하기 위한 모형 중 하나가 연결주의.
- 딥러닝은 바로 이 연결주의를 따름.
딥러닝은 뇌의 뉴런이 얽히고설켜서 연결되어 있는 모양을 본뜬 '인공 신경망'을 모델로 가지고, 신경망은 자극(input)을 받아 내부에서 일련의 정보처리 과정을 거친 후 반응(output)함. 신경망 내부에서는 하나의 데이터를 여러 형태로 바꾸어가며 표현(representation)을 해 나가다가, 최종적으로 우리가 의도한 형태의 데이터를 출력.
딥러닝의 궁극적인 목표
인지주의와 연결주의의 철학과 문제의식을 계승하였으니, "생명체가 데이터를 입력받았을 때 내부에서 정보를 처리하고 표현하는 메커니즘을 알아내는 것"이 딥러닝.
모델링
1. 선형 모델
- 가장 간단한 러닝 모델. 직선(또는 평면, 초평면 등)의 형태로 정의되는 러닝 모델을 특별히 선형 모델(linear model)이라고 부르며, 이는 가장 단순한 러닝 모델에 해당.
- 장점
- 학습 속도가 빠르며 인간이 이해하기 쉬움 대신
- 한계점
- 데이터 자체가 수많은 픽셀로 이루어져 있는 이미지와 같은 데이터의 경우에는 데이터의 복잡성을 선형 모델에 충분히 반영하는 것이 불가능
- 그래서, 실제 이미지 인식 분야에서는 선형 모델 대신 인공신경망(artificial neural networks)과 같은 복잡성이 높은 신경망(neural networks) 구조 러닝 모델을 사용.
2. 신경망
a.k.a.
함수
함수의 역할
1. Relation: x와 y의 관계를 나타낼 수 있는 도구
가 x의 함수라는 말은,
- y는 x의 변화에 종속적이다. 즉 x가 변하면 그 변화하는 정도에 따라 y가 변하게 된다.
- x가 변하는 정도에 따라 y가 얼마나 변하는지는 x와 y의 간 함수의 형태(다항식인지, 삼각함수인지, 혹은 신경망인지 등)로 결정된다.
2. Transformation: x를 변환해 주는 도구
선형함수 (첫 번째, 변환된 축은 여전히 '직선' 형태를 띄어야 한다. 즉, 휘거나 구부러지면 안된다.
두 번째, 변환 후에도 원점(origin)은 이동하지 않아야 한다. 즉, 원점은 그대로여야 한다.)
Transformation은 function(함수)의 fancy한 용어라고 설명한다. (즉, 같은 용어이다.)
특히, 선형대수학에서는 이러한 '변환' 역할을 하는 함수가 변환하기 전의 vector를 입력받아 변환된 후의 vector를 출력한다.
3. Mapping : x의 공간에서 y의 공간으로 매핑해주는 도구
Transformation도 매핑의 일종이지만 더 깊이 스칼라와 벡터로 나눠 매핑을 설명하면,
- 스칼라는 '크기'만 가지고 '방향'은 가지지 않는 양이다. 주로 단 하나의 숫자로 표현한다.
- 벡터는 '크기'와 '방향'을 두 가지 가지는 양이다. 주로 여러 개의 숫자로 표현되며, 좌표 상에서 길이와 방향을 가지는 화살표로 표현한다.
- 매핑방법 3가지
- One-to-One
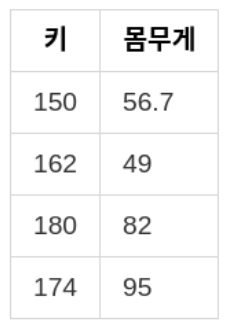
One-to-one 매핑은 입력값 x와 출력값 y가 모두 스칼라인 경우. 단 하나의 값을 입력했을 때, 단 하나의 값만 나옴.
키 - 몸무게 / f(x)=wx+b=y

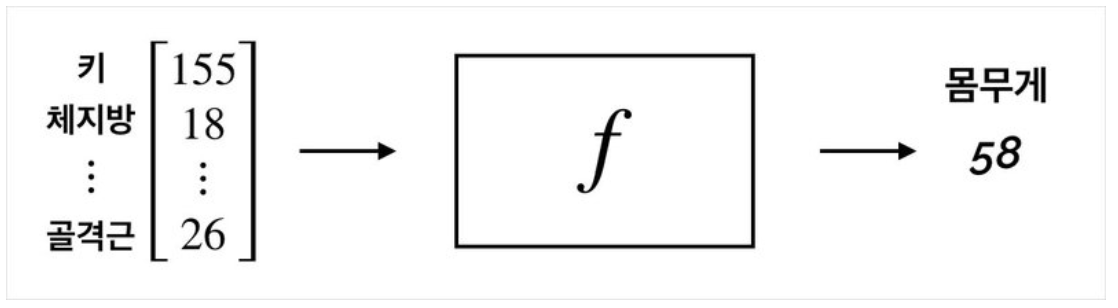
- Many-to-One
Many-to-One은 여러 가지의 정보를 입력받아 하나의 값을 출력. 이 경우 함수는 다음과 같이 벡터인 x를 입력받아 스칼라인 y를 출력하는 형태로 나타낼 수 있음. 이때 일반적으로 벡터는 볼드체로 \mathbf x와 같이 나타냄.

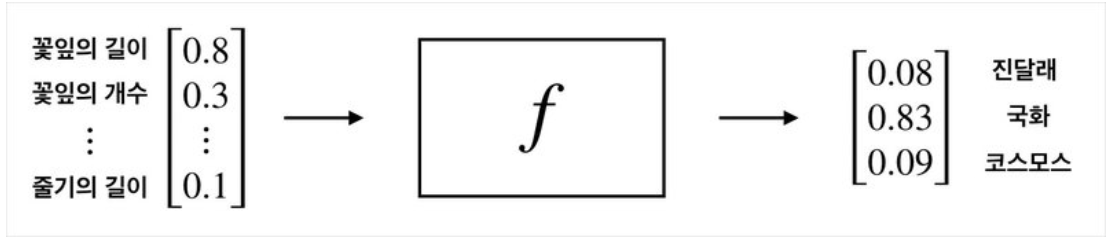
- Many-to-Many
입력값도 벡터, 출력값도 벡터. Many-to-Many가 주로 쓰이는 문제는 바로 '분류' 문제.

함수와 모델의 차이점
함수는 두 점을 지나는 정확한 함수가 정해져 있기 때문에 a와 b, c도 단 한 가지 값으로 정해지지만,
함수는 정확히 단 하나로 정해져있는 함수도 아닐뿐더러, 그 함수가 이차 함수인지, 삼차 함수인지, 혹은 신경망 형태로 나타날지조차 알 수 없다. 우리에게 주어진 것이라곤 단 하나! 데이터뿐.
그렇기에 머신러닝과 딥러닝은 '완벽한 함수'를 찾는 수학 문제를 푸는 것이 아니라, '그나마 가장 잘 근사할 수 있는 함수'에 조금씩 가까워지도록 시도하는 것이 더 정확하다.

그나마 나은 함수를 찾기 위해 해야할 일
1. 모델에 쓸 함수 정하기
모델을 어떤 함수 형태로 나타낼 것인지 함수 공간을 정하는 단계. 선형 함수를 쓸지, 의사결정 나무(Decision Tree) 모델을 쓸지, 혹은 신경망 모델을 쓸지 정해야 하며, 이 과정에서 Inductive Bias가 발생.
- 입력 데이터가 하나인 경우, 즉 One-to-One 문제의 경우에는 f(x)=wx+b와 같은 일차 함수
- 입력 데이터가 여러 개의 특징으로 이루어진 벡터인 경우, 즉 Many-to-One 문제의 경우에는 f(x) = wx_1 + wx_2 + ... + wx_n 과 같은 다변수 선형 함수
- 신경망 모델
다양한 모델(함수) 중 어떤 함수를 채택하느냐는 모델의 최종 성능에 굉장히 중요한 영향을 미친다.
만약 간단한 선형 함수만으로 데이터를 잘 표현할 수 있다고 판단된다면 선형함수를 사용해도 되지만, 이미지나 자연어같이 형태가 고정되지 않은 '비정형 데이터'같은 경우 최근에는 거의 필연적으로 신경망을 사용. (신경망의 구조는 여러 계층이 쌓인 형태이며 이렇게 'Hierarchial(계층적인)' 구조가 비정형 데이터의 표현을 단계별로 잘 추출해낼 수 있다는 것이 실험적으로 보여졌기 때문)
Inductive Bias
- 데이터를 설명할 수 있는 최적의 함수가 특정한 함수 공간에 존재할 것이라는 가설
- Inductive Bias, 혹은 Prior를 가정한다 = 어떤 데이터에 대한 문제를 풀기 위해 '이러한 형태의 함수가 유리할 것'이라고 판단하고 함수 공간을 정하는 것.
- 우리가 학습시킬 모델이 세상의 모든 데이터를 볼 수 없기 때문에 중요. 모델이 학습하는 과정에서 보지 못한 데이터에 대해서도 예측을 잘 하려면(즉, 일반화(Generalization)가 잘 되려면), 일반적인 패턴을 잘 반영할 수 있는 형태의 모델이어야 하고, 좋은 함수로 좋은 모델을 선택하는 것은 우리의 몫
2. 해당 함수 공간 안에서 최적의 함수 찾기
- 이 단계는 즉, model. fit의 단계
- e.g. 신경망의 경우, 경사하강법!
퍼셉트론부터 신경망까지
1. 퍼셉트론
- 입력 벡터 x=(x_1,x_2,...,x_d)를 받아들인 뒤 각 성분에 가중치를 곱하는 선형 모델을 거쳐, 그 결과를 모두 합산한 후 활성화함수 σ(⋅)을 적용한 함수로 이루어진 모델이다. 전체 과정을 수행하는 이 선형 모델을 하나의 함수 h(⋅)로 나타낼 수 있으며, 이를 퍼셉트론(perceptron)이라고 부른다.
- 즉, 퍼셉트론은 선형 함수와 그 결과를 비선형 함수 활성화 함수까지 거치는 합성 함수라고 할 수 있다.
2. 다층 퍼셉트론
- 퍼셉트론은 세 개의 층으로 이루어진다. 입력 벡터가 자리잡는 층을 입력층(input layer), 최종 출력값이 자리잡는 층을 출력층(output layer), 입력층과 출력층 사이에 위치하는 모든 층을 은닉층(hidden layer)이라고 한다.
- 이 때 퍼셉트론을 기본 빌딩 블록으로 하여, 이런 패턴에 따라 2차원적으로 연결되어 구성되는 인공신경망의 일종을 특별히 다층 퍼셉트론(MLP: multi-layer perceptron)이라고 한다.
3. 심층신경망 (DNN)
- 다층 퍼셉트론에서 은닉층의 개수가 많아질수록 인공신경망이 ‘깊어졌다(deep)’고 부르며, 이렇게 충분히 깊어진 인공신경망을 러닝 모델로 사용하는 머신러닝 패러다임을 바로 딥러닝(Deep Learning)이라고 한다.
- 이 때 딥러닝을 위해 사용하는 충분히 깊은 인공신경망을 심층 신경망(DNN: Deep neural network)이라고 한다.
4. 신경망 3가지
- 완전 연결 신경망, 컨볼루션 신경망, 순환 신경망이다.
- 컨볼루션 신경망은 주로 이미지 처리에, 순환 신경망은 주로 자연어 처리에 사용된다.
- 4.1 완전 연결 신경망 ((fully-connected neural network)
- 다층 퍼셉트론을 지칭하는 또 다른 용어
- 완전 연결 신경망은, 위의 다층 퍼셉트론의 일반적 구조에서와 같이 노드 간에 횡적/종적으로 2차원적 연결을 이룹니다. 이 때, 서로 같은 층에 위치한 노드 간에는 연결 관계가 존재하지 않으며, 바로 인접한 층에 위치한 노드들 간에만 연결 관계가 존재한다는 것이 핵심적인 특징
- 4.2 컨볼루션 신경망 (CNN)
- 이미지 인식(image recognition)에 탁월
- 이렇게 컨볼루션 층에서는 현재 필터가 위치한 노드에서, 그 필터가 커버하고 있는, 물리적으로 가까운 곳에 위치한 노드만을 포괄하여 가중합을 계산하는데, 이는 가중치의 개수를 줄여주는 것 외의 또 다른 장점을 제공. 하나의 필터로 하여금 국부(local) 영역에 대한 특징에 집중할 수 있도록 한다는 점. 이러한 특성 때문에, 컨볼루션 필터는 2차원 영역 상의 물리적 거리가 중요한 판단 기준이 되는 이미지 등의 데이터에 대하여 효과적으로 적용될 수 있음.
- 컨볼루션 신경망의 낮은 층에 해당할수록, 이미지 상의 각 세부 영역에서의 경계, 명암, 색상 변화 등 저수준(low-level)의 특징들을 요인 표현으로 포착하는 경향이 있음. 이렇게 위치 별 저수준 요인은, 컨볼루션 신경망의 높은 층으로 올라가면서 서로 가까운 것들끼리 조합되고, 좀 더 넓은 영역에서 고수준(high-level)의 특징들을 요인 표현으로 포착하는 경향을 보임. 이렇게 낮은 층에서는 점, 선, 면과 같은 간단한 요인들을 추출하고, 점점 높은 층에 다다를수록 복잡한 요인들을 추출하며 최종적으로 이미지를 인식.
- 컨볼루션 신경망은 위 그림에서의 자동차 이미지의 바퀴 근처에서 포착되는 저수준 요인들을 통해 점, 선, 면 등의 위치를 파악하고, 이것들을 조합한 고수준 요인을 통해 원형의 사물이 위치하며, 이것이 자동차 바퀴라는 것을 파악. 컨볼루션 신경망의 점점 높은 층으로 올라갈수록 바퀴 외의 주변 사물들도 파악하게 되고, 마지막에는 파악한 내용들을 최종적으로 종합하여 이것이 자동차라는 것을 인식.
- 4.3 연속 신경망 (RNN : recurrent neural network)
- 시퀀스(sequence) 시계열 특징을 가지는 데이터
- 자연어 처리(natural language processing) 분야에 탁월. 사람들이 사용하는 언어를 텍스트 시퀀스 형태의 데이터로 변환하였을 때, 이 또한 길이 가변성과 선후 관계의 특징을 지니기 때문
- 데이터 시퀀스 상의 원소를 매 시점(timestep)마다 하나씩 입력한 후,
- 특정 시점에 나온 은닉층의 출력 벡터(이하 은닉 벡터)를, 시퀀스 상의 바로 다음 원소와 함께 입력.
함께 입력하여 가중합 및 활성함수를 적용하는 구조입니다. 이렇게 은닉 벡터를 그 다음 시점으로 전달하는 이유는, 앞선 시점들에서의 입력 벡터 속 정보들이 현재 시점의 은닉 벡터에 누적되어 있다고 간주하기 때문
참고 링크
https://www.stechstar.com/user/zbxe/index.php?mid=study_SQL&page=14&document_srl=63467
SQL학습 및 DB설계 - 머신러닝이란 무엇인가?
머신러닝이란 무엇인가? Sep 4, 2017 • Introduction • 김길호 Tags: supervised learning, data set, learning model, learning algorithm 수아랩 리서치 블로그 첫 번째 글의 주제는 ‘머신러닝이란 무엇인가?’ 입니다.
www.stechstar.com
https://www.stechstar.com/user/zbxe/index.php?mid=study_SQL&page=13&document_srl=63482
SQL학습 및 DB설계 - 딥러닝이란 무엇인가? (1)
딥러닝이란 무엇인가? (1) Oct 10, 2017 • Introduction • 김길호 Tags: deep learning, deep neural networks, representation learning 수아랩 리서치 블로그 두 번째 글의 주제는 ‘딥러닝이란 무엇인가?’ 입니다. 오늘
www.stechstar.com
https://www.joongang.co.kr/article/22394025#home
못 믿겠다 AI, 설계자도 심층신경망 작동 방식 몰라 | 중앙일보
기계 학습이란 컴퓨터가 스스로 학습해서 데이터로부터 패턴을 파악하는 것을 말한다. 이런 대리인에게 발전소 같은 핵심 인프라를 운영하거나 의학적 결정을 내리게 해도 괜찮을까? 사람들의
www.joongang.co.kr
'Study (Data Science) > DL' 카테고리의 다른 글
| model.summary 에서의 param# 구하기 (0) | 2023.01.06 |
|---|---|
| 활성화함수 종류 (0) | 2022.12.29 |
| TF-IDF (0) | 2022.12.19 |
| 시계열 개념 / ADF Test / 시계열 분해 /ARIMA (0) | 2022.12.18 |
| Loss / Metric (0) | 2022.12.15 |




댓글