- Loss : 모델 학습시 학습데이터(train data) 를 바탕으로 계산되어, 모델의 파라미터 업데이트에 활용되는 함수
- Metric : 모델 학습 종료 후 테스트데이터(test data) 를 바탕으로 계산되어, 학습된 모델의 성능을 평가하는데 활용되는 함수
왜 loss와 metric를 다르게 적용하는가?
분류모델일 경우 loss : crossentropy를 써서 학습시키고, metric : accuracy로 성능을 평가한다.
회귀모델일 경우 loss와 metrics에 RMSE를 둘 다 쓰기도 하고, 또 mse, mae 등 여러가지를 쓴다.
다르게 쓰는 이유는,
loss는 학습을 위해 쓰는 것이기 때문에 학습을 잘 시킬 수 있는 방법을 아는 친구가 적절하고,
(crossentropy는 continuous하기 때문에, discrete한 accuracy보다 학습방향을 훨씬 알려줄 수 있음
accuracy를 loss로 쓰면, 1에 도달하는 순간 이미 완벽하다고 생각해서 더이상 정교한 학습이 안됨. 자만함 ㅋㅋ)
각각의 함수에 대한 이해도 필요하다.
예를 들어 MSE, RMSE는 오차의 제곱에 비례하여 수치가 늘어나므로, 특이값에 민감하게 반응.
그래서 Outlier가 많은 데이터에는 비추.
하지만 MAE, MAPE는 오차의 절대값에 비례해서 수치가 늘어나는데, 상대적으로 특이값에 민감하지 않다.
그래서 Outlier가 많은 데이터에 대해 추천.
즉, loss나 metric으로 어떤 함수를 쓸 지는, 하려는 Task에 따라 다르다. 판단하는건 내 몫!
실제로, tensorflow 시험에서도
Category 1 (단항회귀) : optimizer = adam / loss = mse
Category 2 (분류, mnist) : optimizer = adam / loss = sparse_categorical_crossentropy / metrics = accuracy
Category 3 (이미지증강) : optimizer = RMSprop / loss = categorical_crossentropy / metrics = accuracy
Category 5 (시계열) : optimizer = SGD / loss = huber / metrics = mae
Threshold를 고려하여 classifer의 성능을 평가하는 방법들
Threshod (임계치) 에 대한 내 노트 : (https://nicedeveloper.tistory.com/52)
하나의 함수에도 여러가지 classifer가 있다.
예를 들어 SVM도 ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ 를 가지고 있음.
classifer를 무엇을 쓰는가만 바꿔도 정확도에 영향이 있다.
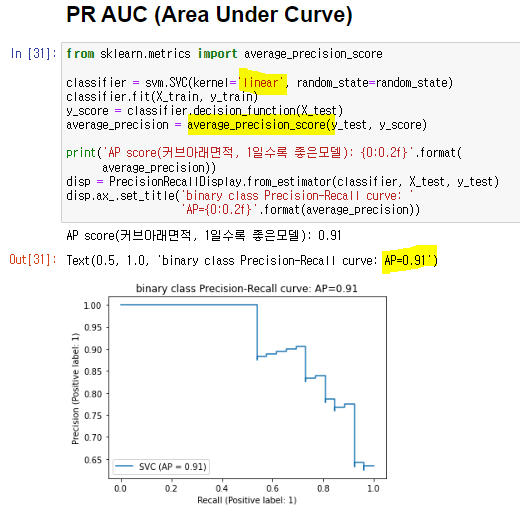
PR(Precision and Recall) 커브
- y축 Precision과 x축 Recall의 trade-off를 보여주는 그래프
- Precision=1, Recall=1이 가장 좋음. 즉 이상치 (1,1)에 근접하게 그려지면 Better.
- 그래서 커브 아랫쪽의 너비값 AUC (Area Under Curve) 를 계산하여 성능을 평가. 1일수록 좋음
- 함수로는 average_precision_score(AP)
ROC(Receiver Operating Characteristic) 커브
- Confusion Matrix 수치로 그리는 그래프
- x축 : FP rate : FP / TN+FP (실제는 음성인데 양성으로 잘못나온 수 / 예측값 상관없이 실제로 음성인 총합)
- 0이 이상치. 잘못예측한 분자가 줄어야함.
- y축 : TP rate : TP / TP+FN (실제로도 예측으로도 양성으로 맞춘경우 / 실제 상관없이 예측값이 음성인 총합)
- 1이 이상치. 정확하게, 그것도 양성으로 예측한 분자가 커야함.
- 이상치 (0,1)에 근접하게 그려지면 Better.
- 그래서 커브 아랫쪽의 너비값 AUC (Area Under Curve) 를 계산하여 성능을 평가. 1일수록 좋음
- 함수로는 roc_curve, auc

다양한 Task별 평가척도
랭킹 모델의 평가척도
정보 검색(Information Retrieval)과 같은 로직 + Ranking 추가
- 종류 : MRR, MAP, NDCG
- NDCG가 제일 좋은 이유 : 랭킹을 매기기 위해 임의성을 배제하고 모든 콘텐츠 아이템에 대한 관련성을 계산하여 랭킹에 반영
- (https://lamttic.github.io/2020/03/20/01.html)
이미지 생성 모델의 평가척도
원본 이미지와 새로운 이미지 사이의 거리를 어떻게 측정할 것인가.
- 종류 : MSE, PSNR , SSIM
- SSIM가 제일 좋은 이유 : MSE나 PSNR은 모두 픽셀 단위로 비교해서 거리를 측정한다. 그러나 이 방식은 이미지가 약간 평행이동해 있어도 두 차이를 크게 측정하는 단점이 있다. SSIM은 이와 달리 픽셀 단위 비교보다는 이미지 내의 구조적 차이에 집중하는 방식을 쓴다.
- (https://medium.com/@datamonsters/a-quick-overview-of-methods-to-measure-the-similarity-between-images-f907166694ee)
기계번역 모델의 평가척도
텍스트 번역. 원본 텍스트와 새로운 텍스트의 오차를 어떻게 측정할 것인가.
- BLEU score : x, y 각각 문장(시리즈)일 때, 두 텍스트가 얼마나 겹치는지를 측정하는 척도
- 1-gram, 2-gram, 3-gram, 4-gram이 두 문장 사이에 몇번이나 공통되게 출현하는지를 측정
- (https://donghwa-kim.github.io/BLEU.html)
'Study (Data Science) > DL' 카테고리의 다른 글
| model.summary 에서의 param# 구하기 (0) | 2023.01.06 |
|---|---|
| 활성화함수 종류 (0) | 2022.12.29 |
| 인공지능, 머신러닝 그리고 딥러닝 (4) | 2022.12.27 |
| TF-IDF (0) | 2022.12.19 |
| 시계열 개념 / ADF Test / 시계열 분해 /ARIMA (0) | 2022.12.18 |




댓글