












- Scikit Learn : 파이썬 기반 머신러닝 라이브러리. Scipy 및 NumPy 와 비슷한 데이터 표현과 수학 관련 함수
- 일반적으로 머신러닝에서 데이터 가공(ETL:Extract Transform Load)을 거쳐 모델을 훈련하고 예측하는 과정을 거침
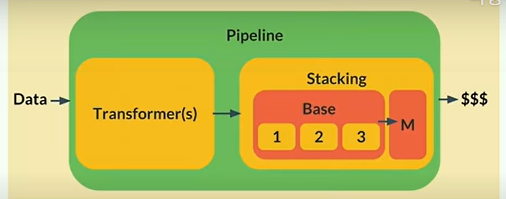
- Scikit Learn은 ETL - transformer()를 제공하고, 모델의 훈련과 예측은 Estimator 객체를 통해 수행되며, Estimator에는 각각 fit()(훈련), predict()(예측)을 행하는 메소드가 있음. 모델의 훈련과 예측이 끝나면 이 2가지는 작업을 Pipeline()으로 묶어 검증을 수행.
- data >> transformer() >> estimator.fit(X,y) >> estimator.predict(X) >> Pinpeline(model)
- |----------------meta-estimator----------------|
데이터 표현법
NumPy의 ndarray, Pandas의 DataFrame, SciPy의 Sparse Matri를 사용해 나타낼 수 있음.
특성 행렬 X, n_samples & 타겟 벡터 y, n_samples = 동일해야 함.
- 특성 행렬(Feature Matrix) : X값
- 특성 : X값에 해당하는 모든 열의 속성. 나이, 몸무게, 키, 성별 등등
- [n_samples, n_features] : 행의 갯수(표본의 갯수), 열의 갯수 (특성의 갯수)
- 타겟 벡터(Target Vector) : y값,= label, = 구해야하는 답
- n_feature는 없음. 왜? 답이니깐,,
- n_sample : 행의 갯수(표본의 갯수)
- 보통 1차원 벡터로 나타내며, Numpy ndarray나, pandas의 Series로 나타냄
- 1차원이 아닐 수도 있음.

데이터셋 준비
from sklearn.model_selection import train_test_split
result = train_test_split(X, y, test_size=0.2, random_state=42)
train_test_split은 비율에 따라 자동으로 train, test를 나눠주는 아주 똑똑한 친구.
나는 왜 이때까지 pandas로 slicing 했었나 돌아보게 된다..
Estimator
Estimator은 scikit-learn 이 제공하는 머신모델을 쉽게 사용하게 해주는 모듈
예시) model = RandomForestClassifer(), LinearRegression(), PCA()
model.fit(X_train,y_train) : 답이 있는 지도학습에서는 y (타겟벡터)를 인자로 써서 수행하고,
model.fit(X_train ) : 답이 없는 비지도학습에서는 따로 타겟벡터 없이 특성행렬만 넣어 수행할 수 있다.
y_test=model.predict(X_test) : 예측
결과 확인
print(classification_report(y_test, y_pred)) - matrix 형태
print("정답률=", accuracy_score(y_test, y_pred)) - accuracy만 보여줌
728x90
'Study (Data Science) > ML' 카테고리의 다른 글
| 문자열다루기, 정규표현식 (0) | 2022.12.08 |
|---|---|
| Matplotlib, Seaborn (0) | 2022.12.07 |
| 알고리즘 선택하기 (0) | 2022.12.07 |
| 오차행렬, FP, FN, F-score, Threshold (0) | 2022.12.07 |
| Batch size, Epoch, Iteration (0) | 2022.12.06 |




댓글