(1) Dicision Tree (Iris Accuracy : 0.90)
- 분류, 회귀 모두 가능
- 한번 분기 때마다 변수 영역을 두 개로 구분하는 모델. 가지 두개로 나눠짐.
- 정보획득(information gain)의 기준 : 구분 뒤 각 영역의 순도(homogeneity)가 증가, 불순도(impurity), 불확실성(uncertainty)이 최대한 감소방향으로 학습진행
(2) Random Forest (Iris Accuracy : 0.93)
- Decision Tree를 모아 집단지성의 개념으로 기존 모델의 단점을 보완함.
- 앙상블 방식(Ensemble method)
- 랜덤으로 여러 작은 트리를 만들어 각각의 트리에서 나오는 결과를 다수결하여 최종결정
- 예) 30개의 feature (x값의 갯수 = 컬럼갯수와 같이 다양한 정보의 섹션수) 중에 5개만 선택해서 하나의 나무를 만들고, 이를 반복하여, 결과를 다수결함
- 분류 : 여러개의 나무들의 예측값중 최빈값 / 회귀 : 평균
(3) Support Vector Machine (SVM) (Iris Accuracy : 0.97)
- Support Vector와 Hyperplane(초평면)을 이용해서 분류를 수행하게 되는 대표적인 선형 분류 알고리즘
- Decision Boundary(결정 경계): 두 개의 클래스를 구분해 주는 선
- Support Vector: Decision Boundary에 가까이 있는 데이터. 데이터가 아무리 많아도 분류작업 시에는 support vector가지고만 연산. 효율적임.
- Margin: Decision Boundary와 Support Vector 사이의 거리. 마진이 넓을수록 분류가 잘됨.
- cost: Decision Boundary와 Margin의 간격 결정.
cost가 높으면 Margin이 좁아지고(분류는 잘안되고), train error가 작아진다.
그러나 새로운 데이터에서는 분류를 잘 할 수 있다.
cost가 낮으면 Margin이 넓어지고, train error는 커진다 - γ(gamma): 한 train data당 영향을 미치는 범위 결정.
γ가 커지면 영향을 미치는 범위가 줄어들고,
Decision Boundary에 가까이 있는 데이터만이 선의 굴곡에 영향을 준다.
따라서 Decision Boundary는 구불구불하게 그어진다. (오버피팅 초래 가능)
작아지면 데이터가 영향을 미치는 범위가 커지고, 대부분의 데이터가
Decision Boundary에 영향을 준다.
- 따라서 Decision Boundary는 직선에 가까워진다.
- Margin이 넓을수록 새로운 데이터를 잘 구분할 수 있다.
(Margin 최대화 -> robustness 최대화)


사과, 오렌지 이렇게 이중분류만 하면 될때에는 SVM이 boundary 직선 1개 그어도 잘 분류가 되는데,
사과, 오렌지, 메론 ,포도같이 다중분류일 때에는 하나의 직선으로 이들을 분류할 수가 없다.
하지만 이들이 2차원 공간에 있어서 하나의 선으로 분류가 되지 않는 것이기 때문에,
더 고차원으로 깊이를 추가하면 하나의 선으로 (물론 곡선이 되겠지만) 분류가 가능하다. (Linear SVM)
이 때에 마진과 경계간의 거리를 조절하는 cost 나, 데이터의 영향범위를 결정하는 gamma라는 파라미터가 나오고, 이 둘은 경계를 결정하는 중요한 요소가 된다.
어떤값을 넣어야 할 지는 우리 몫이지만,
이 때 가장 좋은 값을 찾아주는 친구가 Grid Search 이다.
(4) Stochastic Gradient Descent Classifier (SGD Classifier) : 확률적 경사하강법
(Iris Accuracy : 0.87)
- 배치 크기가 1인 경사하강법 알고리즘. 데이터 세트에서 무작위로 균일하게 선택한 하나의 데이터 포인트를 이용하여 각 단계의 예측 경사를 계산
- Batch 경사 하강법 1회에 사용되는 데이터의 묶음. 1 epoch당 사용되는 training dataset의 묶음. 단일 반복에서 기울기를 계산하는 데 사용하는 예(data)의 총 개수
- Epoch : 훈련 세트를 한 번 모두 사용하는 과정
- 배치의 크기에 따라 경사 하강법이 달라짐
- Batch Size = 전체 학습 데이터: 배치 경사 하강법(BGD)
- Batch Size = 1: 확률적 경사 하강법(SGD)
- Batch Size = batch_size(사용자 지정): 미니 배치 확률적 경사 하강법(MSGD)
- 보통 SGD라 함은 미니 배치 확률적 경사 하강법을 의미함
- 확률적 SGD의 단점
- 배치 크기가 1이다보니, 데이터 전체가 1 배치안에 있음. 파라미터가 하나 이동할
때마다 모든 데이터를 계산해야해서 값이 너무 많고, 시간,메모리 낭비가 많음 - 배치 1개 안에서 예 1개를 무작위 선택(=확률적) 하기 때문에, 노이즈도 많고 반복도 많음. 경사하강의 최저점을 찾지 못할 수도 있음.
- 배치 크기가 1이다보니, 데이터 전체가 1 배치안에 있음. 파라미터가 하나 이동할
- 미니배치 SGD
- 보완모델. 전체 데이터를 batch_size개씩 나눠 배치로 학습시킴.
- 배치 크기는 사용자가 지정.1,000개인 학습 데이터 셋에서 batch_size를 100으로 잡았으면 총 10개의 mini batch가 나오고, 이 100개씩의 mini batch를 갖고, 한 번씩 SGD를 진행. 1 epoch 당 총 10번의 SGD를 진행함
- 장점과 단점
- 최적해에 더 가까이 도달할 수 있으나 local optima 현상 발생할 수 있음.
but. local optima의 문제는 무수히 많은 임의의 parameter로부터 시작하면 해결 → 학습량을 늘리면 해결됨! - 배치 크기는 총 학습 데이터 셋의 크기를 배치 크기로 나눴을 때 딱 떨어지는 크기가 좋음. - 1,050개의 데이터 셋이 있을 때 batch_size를 100으로 하면 마지막 50개는 과도한 평가를 할 수 있기 때문에 버리는 것이 좋음.
- Stochastic 방법은 1회 학습당 계산량이 줄어들고, shooting이 발생해 local minima를 피할 수 있음
- Mini-Batch 는 전체 학습데이터를 배치 사이즈로 나누어서 순차적으로 진행함. 2의 n승이 좋음.
- 최적해에 더 가까이 도달할 수 있으나 local optima 현상 발생할 수 있음.
- Batch 보다 빠르고 SGD 보다 낮은 오차율을 가진다는 장점이 있음
(5) Logistic Regression (Iris Accuracy : 0.97)
- 대표적인 다중 클래스 분류함수. softmax. Softmax Regression이라고도 하지만 사실상 분류모델이다.
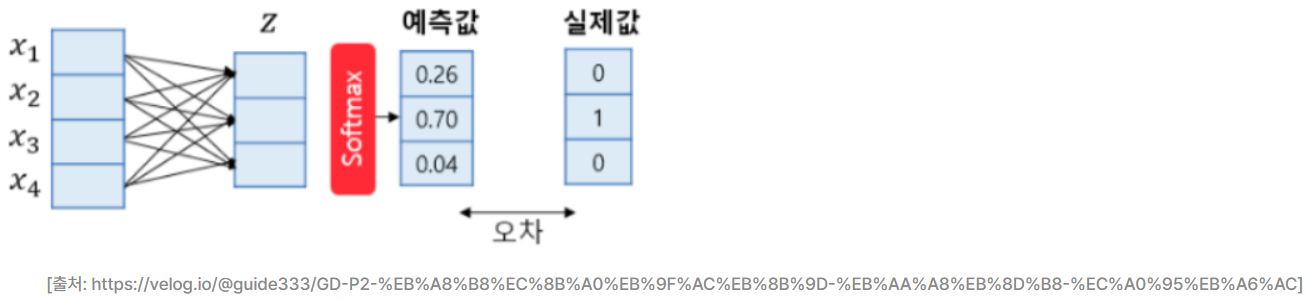
- 클래스가 N개일 때, N차원의 벡터가 각 클래스가 정답일 확률을 표현하도록 정규화를 해주는 함수. 그림은 4차원의 벡터를 입력으로 받아 3개의 클래스를 예측하는 경우. 3개의 클래스 중 1개의 클래스를 예측해야 하므로 소프트맥스 회귀의 출력은 3차원의 벡터고, 각 벡터의 차원은 특정 클래스일 확률. 오차와 실제값의 차이를 줄이는 과정에서 가중치와 편향이 학습됨.
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
의사결정나무(Decision Tree) · ratsgo's blog
이번 포스팅에선 한번에 하나씩의 설명변수를 사용하여 예측 가능한 규칙들의 집합을 생성하는 알고리즘인 의사결정나무(Decision Tree)에 대해 다뤄보도록 하겠습니다. 이번 글은 고려대 강필성
ratsgo.github.io
[혼공머] 배치와 미니 배치, 확률적 경사하강법
👩🔬 이번에는 혼공머 책의 챕터 4-2 파트입니다.📚 혼자공부하는머신러닝+딥러닝, 한빛미디어📄 Gradient Descent - 경사하강법, 편미분, Local Minimum📑 경사하강법(Gradient Descent)🔗 배치와 미니
velog.io
'Study (Data Science) > ML' 카테고리의 다른 글
| 오차행렬, FP, FN, F-score, Threshold (0) | 2022.12.07 |
|---|---|
| Batch size, Epoch, Iteration (0) | 2022.12.06 |
| Day2. 데이터 전처리 (0) | 2022.12.05 |
| Day1. 데이터, 데이터베이스 (0) | 2022.12.04 |
| EDA (Explratory Data Analysis) (1) | 2022.12.02 |




댓글