1. lib import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2. 데이터 불러오기
data = pd.read_csv('이름', low_memory = False)
3. 데이터 null값 처리
data.info() : null값과 자료형 보여줌
data.isnull().sum() : null값이 column별로 몇개인지 보여줌.
data["컬럼명"].replace("카테고리명", "0") : 해당 컬럼의 해당카테고리명인 데이터를 모두 0으로 바꿔줌
4. 데이터 분석
data.head()
data.tail()
data.columns : 전체 컬럼명
data.describe() : 기본적인 통계데이터 보여줌.
----
value_counts().: 값을 카운팅 하겠다.
data['컬럼명'].value_counts().sum() : 해당컬럼의 값을 카운팅하여 sum 하겠다.
data['컬럼명1']..corr(data['컬럼명2'].) : 해당 두 컬럼 사이의 상관관계를 보겠다.
data.drop([컬럼명'] : remove
data['컬럼명1'].groupby(data['컬럼명2']) : 데이터 1을 데이터 2 기준으로 묶어줘. (월급(1)을 성별(2)별로 묶어줘)
.size() : 데이터가 몇개인가. 횟수를 알려주는 인덱스가 되기도 함. (성별별 월급 평균 구한 후, 여자가 받은팁의 횟수)
.unique() : 컬럼안에 범주명 한개씩 뽑아줌.
- data의 TotalPay(OvertimePay 아님 ㅎ)를 년도별 평균을 내어 y에 저장(4개 숫자)
- y = data['TotalPay'].groupby(data['Year']).mean()
- data의 Year를 x에 저장(4개 숫자)
- x = data['Year'].unique()
- count(): NA를 제외한 수를 반환합니다.
- describe(): 요약 통계를 계산합니다.
- min(), max(): 최소, 최댓값을 계산합니다.
- sum(): 합을 계산합니다.
- mean(): 평균을 계산합니다.
- median(): 중앙값을 계산합니다.
- var(): 분산을 계산합니다.
- std(): 표준편차를 계산합니다.
- argmin(), argmax(): 최소, 최댓값을 가지고 있는 값을 반환합니다.
- idxmin(), idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환합니다.
- cumsum(): 누적 합을 계산합니다.
- pct_change(): 퍼센트 변화율을 계산합니다.
연습문제 코드
1. import 정리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
------------------------------------------------
2. 데이터 불러오기
data = pd.read_csv('Salaries.csv', low_memory = False)
------------------------------------------------
3. x,y축 설정
* data의 TotalPay(OvertimePay 아님 ㅎ)를 년도별 평균을 내어 y에 저장(4개 숫자)
* data의 Year를 x에 저장(4개 숫자)
y = data['TotalPay'].groupby(data['Year']).mean()
y
x = data['Year'].unique()
x
------------------------------------------------
4. matplotlib, seaborn을 이용하여 각각 barplot을 그려보자
* 결과물이 다음 그래프와 동일하게 나와야 함
* 1번(plt)의 그래프 색은 빨강, 파랑, 분홍, 초록이며, 2번(sns)의 그래프 색은 twilight(palette설정 검색)
* 그래프 크기도 조절하여 최대한 맞춰볼 것
fig = plt.figure(figsize = (10,5))
ax1 = fig.add_subplot(1,2,1)
plt.bar(x,y,color=['r','b','pink','g'])
plt.xticks([2011,2012,2013,2014])
ax2 = fig.add_subplot(1,2,2)
sns.barplot(data=data,x=x,y=y,palette='twilight')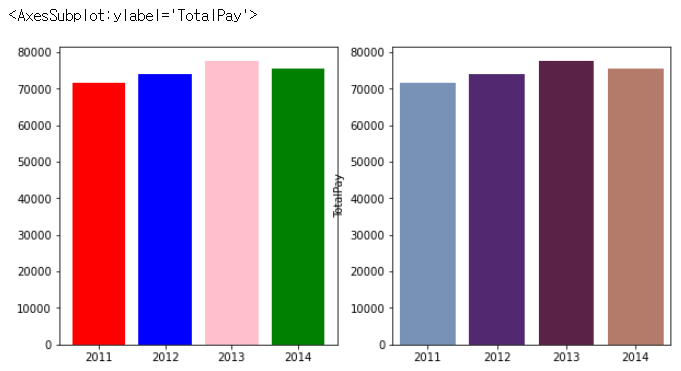
📈 seaborn vs pandas plot 정리
사용 데이터셋 (현재 이 데이터셋은 폐기 되었다고 나온다.) 위 공공데이터를 사용하여 인프런강의 (공공데이터로 파이썬 데이터 분석) 의 방법으로 전처리한 데이터로 시각화 정리를 진행한다.
velog.io
728x90
'Study (Data Science) > ML' 카테고리의 다른 글
| Batch size, Epoch, Iteration (0) | 2022.12.06 |
|---|---|
| 여러가지 머신러닝 모델들 (0) | 2022.12.06 |
| Day2. 데이터 전처리 (0) | 2022.12.05 |
| Day1. 데이터, 데이터베이스 (0) | 2022.12.04 |
| Matplotlib (0) | 2022.12.02 |




댓글